
上一篇
如何在迭代过程中优化MapReduce算法以提高性能?
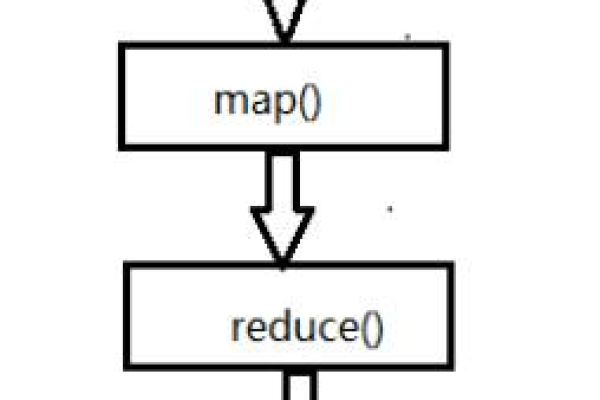
迭代MapReduce是一种编程模型,用于处理和生成大数据集。它通过将任务分为映射(Map)和归约(Reduce)两个阶段来简化数据处理过程。在迭代MapReduce中,输入数据经过多次Map和Reduce操作,每次迭代都会更新数据并产生新的输出,直到满足终止条件。这种方法适用于需要多轮处理的复杂数据分析任务。
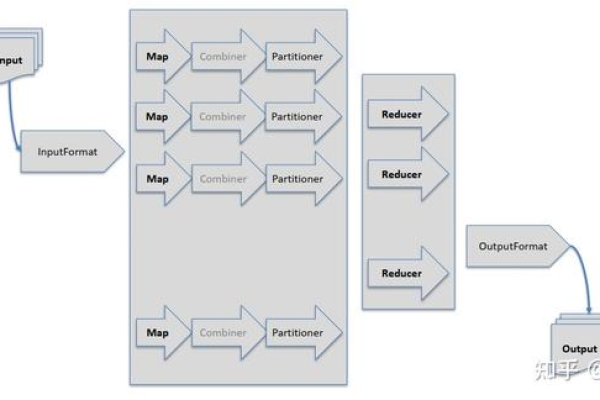
迭代MapReduce是一种编程模型,用于处理大量数据的并行计算,它由两个主要阶段组成:Map阶段和Reduce阶段,下面是一个详细的迭代MapReduce的步骤和示例代码:

1、Map阶段:将输入数据分割成多个独立的块,并对每个块应用一个映射函数(map function),映射函数接收一个键值对作为输入,并生成一组中间键值对作为输出,这些中间键值对将被传递给Reduce阶段。
2、Shuffle阶段:将所有具有相同中间键的中间键值对分组在一起,以便后续的Reduce操作可以处理它们,这个过程通常涉及到网络传输和磁盘I/O。
3、Reduce阶段:对于每个唯一的中间键,执行一个归约函数(reduce function),该函数接收与该键关联的所有中间值作为输入,并生成一个或多个输出键值对,最终的结果被收集并返回给调用者。
下面是一个简单的迭代MapReduce的例子,用于计算文本文件中单词的出现次数:
from collections import defaultdict
import itertools
def map_function(document):
"""Map function that splits the document into words and counts their occurrences."""
words = document.split()
word_count = defaultdict(int)
for word in words:
word_count[word] += 1
return word_count.items()
def reduce_function(item):
"""Reduce function that sums up the counts of each word."""
word, count = item
return (word, sum(count))
Example input data
documents = [
"hello world",
"hello again",
"goodbye world"
]
Map phase
intermediate = []
for document in documents:
intermediate.extend(map_function(document))
Shuffle phase is implicitly handled by thegroupby function
Sorting the intermediate data by key to group them together
sorted_intermediate = sorted(intermediate, key=lambda x: x[0])
grouped_intermediate = itertools.groupby(sorted_intermediate, key=lambda x: x[0])
Reduce phase
result = {}
for key, group in grouped_intermediate:
group_list = list(group)
result[key] = reduce_function(group_list)
print(result)在这个例子中,我们首先定义了map_function和reduce_function,我们对输入文档列表中的每个文档应用map_function,并将结果存储在intermediate列表中,我们对intermediate列表进行排序和分组,以便我们可以将其传递给reduce_function,我们遍历分组的数据并应用reduce_function,得到每个单词的总计数。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/67401.html
相关文章

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
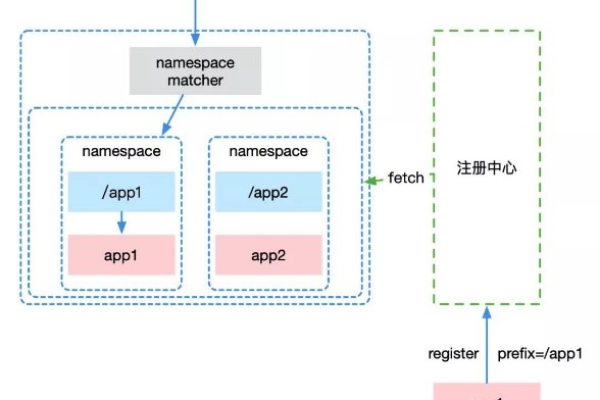
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
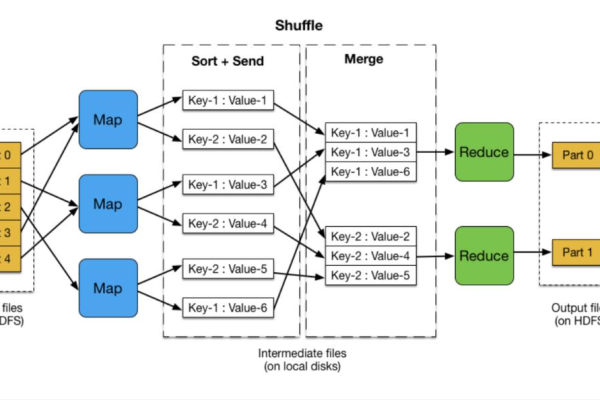
如何优化MapReduce节点以提高MRS MapReduce作业的性能?
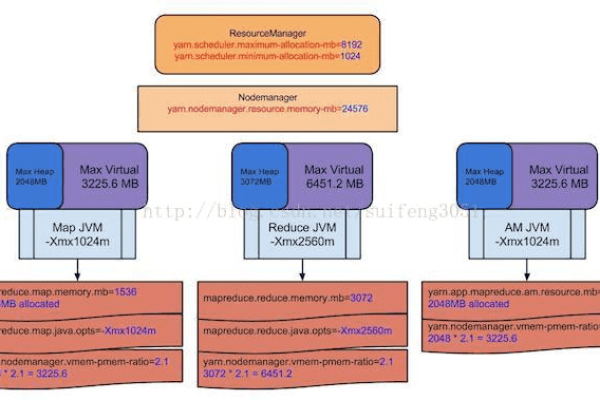
如何正确配置mapreduce.map.tasks参数以优化MapReduce作业性能?
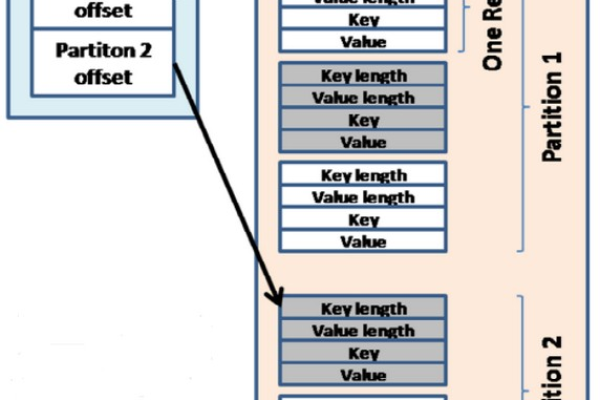
MapReduce Shuffle调优,如何优化MapReduce中的Shuffle过程?
如何优化MapReduce算法中的排序过程?
MapReduce算法在排序过程中的优化策略有哪些,如何实现高效排序?
如何优化MapReduce中map阶段的key处理以提高性能?








