
上一篇
如何有效采集JavaScript生成的网页内容?
您的问题没有提供具体的内容,因此我无法为您生成摘要。如果您希望我帮您从一段文本中提取关键信息并生成摘要,请提供具体的文本内容。您可以提供一篇文章、一段对话或者一段描述,然后我可以从中提取主要观点和关键信息,为您生成一段简洁明了的摘要。
采集JavaScript内容的步骤

获取HTML源代码
1、创建XMLHttpRequest对象:
使用var xhr = new XMLHttpRequest();初始化一个XMLHttpRequest对象。
2、发送HTTP请求:
使用xhr.open('GET', url, true);指定请求类型、URL和是否异步。
使用xhr.send();发送请求。
3、监听请求状态变化:
通过xhr.onreadystatechange监听状态变化,在回调函数中处理响应数据。
解析HTML源代码
1、访问DOM节点:
使用DOM对象的方法和属性访问和操作HTML元素。
2、提取需要的内容:
根据DOM结构,使用适当的方法如getElementById或querySelector等来定位和提取信息。
输出结果
1、使用console.log输出:
将采集到的数据通过console.log打印到控制台。
2、其他输出方法:
可以根据需求选择不同的输出方式,如写入文件或发送网络请求。
方法和工具
WebBrowser控件
1、DocumentCompleted事件:
在文档加载完成后触发,用于执行内容获取操作。
2、判断页面加载完成:
确保是本页面完全加载完毕,而非iframe等子框架。
PhantomJS
1、自动化脚本:
PhantomJS提供了编写自动化脚本的能力,模拟浏览器行为。
2、页面交互:
可以模拟用户交互,如点击和填写表单,以加载动态内容。
Splash
1、模拟滚动:
修改Splash代码以模拟页面滚动,加载更多内容。
2、数据检索:
确保加载所有数据后,检索所需的HTML内容。
相关问题与解答
Q1: 使用XMLHttpRequest获取的源代码包括动态生成的内容吗?
A1: 不包括,XMLHttpRequest仅获取初始HTML代码,动态生成的内容需要通过模拟浏览器行为的工具如Selenium或PhantomJS来获取。
Q2: PhantomJS和Puppeteer有什么区别?
A2: PhantomJS是一个早期的无头浏览器,已不再维护;而Puppeteer是一个基于Chromium的Node库,功能更全面且支持最新的JavaScript特性和浏览器特性。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/44316.html
相关文章
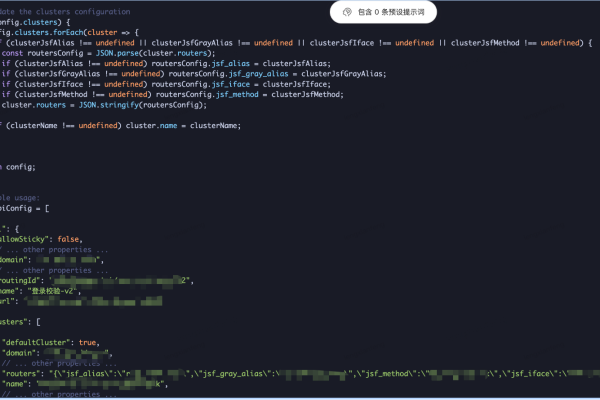
如何有效采集JavaScript生成的内容?
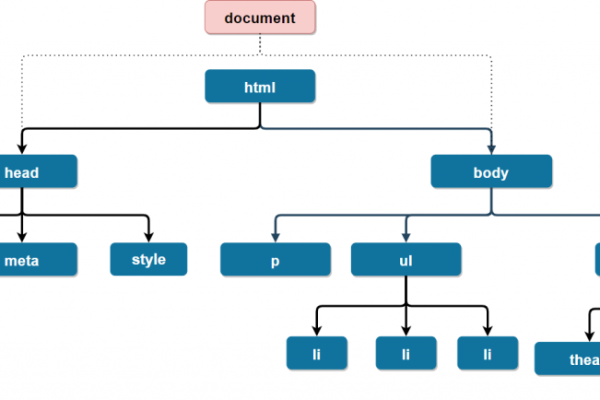
js dom树 是一个关于JavaScript和文档对象模型(DOM)的概念。在生成一个原创的疑问句标题时,我们可以围绕这个概念提出一个问题,以吸引读者的注意并引发他们的好奇心。以下是一个可能的标题,,如何有效地遍历和操作JavaScript中的DOM树?,提出了一个关于如何在JavaScript中高效地处理DOM结构的问题,这可能会吸引那些对前端开发和网页脚本编程感兴趣的读者。

js 美元符号这个短语可能指的是JavaScript编程语言中的美元符号($),它通常用于引用jQuery对象。然而,由于提供的信息非常有限,很难确定确切的含义或上下文。因此,我将基于假设的上下文生成一个疑问句标题,,如何在JavaScript中使用美元符号($)进行DOM操作?,假设文章是关于如何使用JavaScript中的美元符号来操作文档对象模型(DOM)的。如果文章有其他含义或上下文,请提供更多信息以便生成更准确的标题。

javascript如何关闭当前页面,手机如何关闭javascript「手机可关闭javascript」
如何通过精通Javascript系列之Javascript基础篇提升你的JavaScript技能?

js中text 是一个不完整的短语,因此无法直接为它生成一个原创的疑问句标题。不过,假设您想探讨 JavaScript 中的文本处理,我可以提供一个相关的疑问句标题,,如何在JavaScript中高效地操作和处理文本数据?
js qq截图这个短语可能指的是使用JavaScript实现QQ截图功能。基于此,一个原创的疑问句标题可以是,,如何使用JavaScript在网页上实现类似QQ截图的功能?

High Performance JavaScript(高性能JavaScript)读书笔记分析ja








