
上一篇
如何解决MySQL数据库中Hudi表自动建表时因schema不匹配导致的报错问题?
在使用Hudi表时,如果遇到schema不匹配导致建表失败的问题,你可以尝试以下方法解决:,,1. 检查并确保你的Hudi表的schema与你的数据源(如MySQL表)的schema完全一致。,2. 如果存在不一致,你需要更新 Hudi表的schema以匹配数据源的schema。,3. 确保在创建Hudi表时使用正确的schema定义。,,如果你的数据源表有一个名为”column_name”的列,而Hudi表中没有这个列,你需要在Hudi表的schema中添加这个列。
在使用Hudi进行表的自动创建时,如果出现“schema不匹配,建表失败”的错误,这通常是由于Hudi在尝试根据提供的数据或schema创建表时,发现实际数据的schema与预期的schema不一致所导致的,为了解决这个问题,我们需要从多个方面进行分析和调整。

1. 理解Hudi的Schema演化
需要理解Hudi如何处理schema的演化,Hudi支持两种schema演化策略:
字段添加策略(Schema Evolution with Field Addition):允许在表中新增列,而不会影响现有查询。
全表替换策略(Schema Evolution with Full Table Replacement):如果schema发生任何变化,需要重新写入整个表。
2. 检查数据源的Schema
确保你提供给Hudi的数据源(如Kafka, HDFS等)中的数据集schema与Hudi所期望的schema一致,可以使用如下命令查看Hudi表的schema:
SELECT * FROM hudi_table LIMIT 0;
将此schema与你的数据源中的数据schema进行对比,确保所有字段名称、类型和顺序都一致。
3. 使用正确的Hudi版本
确保你使用的Hudi版本支持你的数据源格式和schema演化需求,不同版本的Hudi可能在schema处理上有所不同,特别是对于复杂的schema演化场景。
4. 更新Hudi配置
在Hudi的配置中,可能需要调整以下参数来适应不同的schema演化需求:
hoodie.table.schema.resolution:控制如何处理schema解析,可以设置为INHERITED,FULL_TABLE,FIELD_ADDITION。
hoodie.datasource.write.recordkey.field 和hoodie.datasource.write.partitionpath.field:指定记录键和分区路径字段。
5. 手动干预Schema
如果自动schema匹配失败,可以考虑手动定义schema,并在创建Hudi表时指定这个schema。
CREATE TABLE hudi_table ( id INT, name STRING, timestamp TIMESTAMP ) USING hudi OPTIONS ( 'hoodie.datasource.write.recordkey.field'='id', 'hoodie.datasource.write.partitionpath.field'='timestamp' );
确保这里的schema与数据源完全一致。
6. 逐步调试和验证
在解决了上述问题后,建议逐步调试并验证每一步操作:
先测试小数据集上的schema匹配。
逐步扩大测试范围,直到满足生产需求。
7. 考虑使用工具辅助
使用像Apache NiFi, StreamSets这样的数据流工具可以帮助你在数据到达Hudi之前预处理和验证schema,确保数据格式的正确性。
相关FAQs
Q1: Hudi表创建时如何指定自定义Schema?
A1: 在创建Hudi表时,可以通过在CREATE TABLE语句中明确列出所有字段及其类型来指定自定义Schema,如上面第5点所示。
Q2: 如果数据源的Schema经常变化,我该如何管理?
A2: 如果数据源的Schema经常变化,建议采用Hudi的Field Addition策略,这样你可以在不重写整表的情况下添加新字段,监控数据源的变化,及时更新Hudi表的Schema以适应这些变化。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/42417.html
相关文章
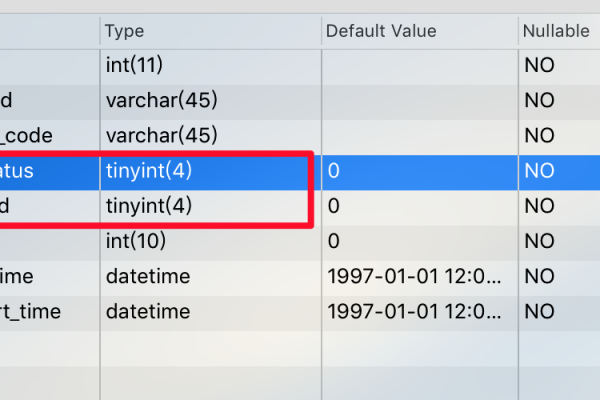
如何解决MySQL中Hudi表自动建表时因schema不匹配导致的建表失败问题?
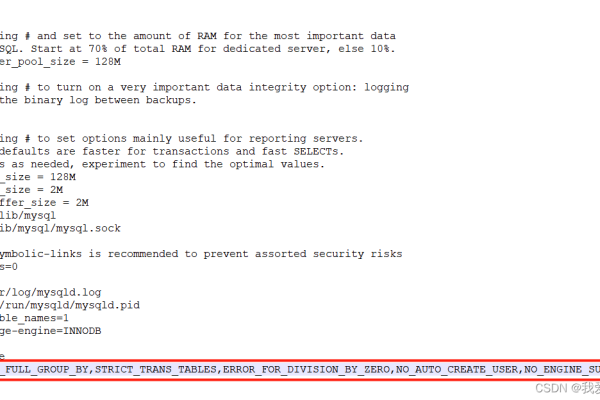
MySQL建表时遇到Hudi表自动建表报错,schema不匹配导致建表失败,该如何解决?
如何通过代码解决MySQL数据库中Hudi表自动建表时的schema不匹配问题?

如何解决Hudi表在MySQL中因schema不匹配导致的自动建表错误?

如何解决Hudi表在MySQL中自动创建时因schema不匹配而导致的建表失败问题?
解决Hudi表自动建表时遇到的schema不匹配问题,如何正确创建MySQL数据库?

如何在MySQL中创建两个数据库表时解决Hudi表自动建表的schema不匹配错误?
如何解决Hudi表自动建表时出现的schema不匹配错误?








