
上一篇
c存储中文
C语言中文存储方法在C语言中, 存储 中文字符可以通过多种方式实现。常见的方法包括使用宽字符类型(如wchar_t)、UTF-8编码和专用库进行编码转换。推荐使用UTF-8编码,因为它是国际通用标准,兼容性好且占用空间相对较小。
在C语言中,处理中文字符可能会遇到一些挑战,因为C语言本身是面向ASCII字符集设计的,通过使用宽字符和适当的编码标准,我们可以在C程序中存储和处理中文字符,以下是关于如何在C语言中存储中文的详细指南。
理解字符编码
ASCII:标准的ASCII编码只能表示英文字母、数字和一些符号,无法直接表示中文字符。
UTF-8:一种可变长度的字符编码,可以表示全世界所有的字符,包括中文,一个中文字符通常占用3个字节。
UTF-16:另一种常用的Unicode编码形式,中文字符通常占用2个字(4个字节)。
使用宽字符类型
在C语言中,wchar_t类型用于表示宽字符,通常是16位或32位,可以存储UTF-16或UTF-32编码的字符。
#include <wchar.h>
#include <locale.h>
int main() {
setlocale(LC_ALL, ""); // 设置本地化信息,以便正确显示宽字符
wchar_t chinese_char = L'你'; // 定义一个宽字符变量并赋值为中文字符“你”
wprintf(L"%lc
", chinese_char); // 使用%lc格式说明符打印宽字符
return 0;
}字符串操作
对于宽字符串(即由wchar_t组成的字符串),可以使用<wchar.h>头文件中提供的函数,如wcslen,wcscpy,wcscat等。
#include <wchar.h>
#include <stdio.h>
#include <locale.h>
int main() {
setlocale(LC_ALL, "");
wchar_t str[] = L"你好,世界!"; // 定义一个宽字符串
wprintf(L"%ls
", str); // 使用%ls格式说明符打印宽字符串
return 0;
}文件操作中的中文处理
当读写包含中文的文件时,需要确保文件以正确的编码方式打开,并使用相应的库函数来处理宽字符。
#include <wchar.h>
#include <stdio.h>
#include <locale.h>
int main() {
setlocale(LC_ALL, "");
FILE *file = fopen("example.txt", "w,ccs=UTF-8"); // 以UTF-8编码打开文件
if (file == NULL) {
perror("Failed to open file");
return 1;
}
fwprintf(file, L"你好,文件!
"); // 写入宽字符串到文件
fclose(file);
return 0;
}常见问题与解答
Q1: 为什么需要在代码中调用setlocale(LC_ALL, "")?
A1:setlocale函数用于设置程序的区域设置信息,这会影响程序如何处理宽字符和多字节字符,通过传递空字符串""作为参数,程序将采用系统的默认区域设置,从而能够正确地处理和显示本地化的字符。
Q2: 如果我不使用宽字符,而是直接使用char数组来存储UTF-8编码的中文字符会怎样?
A2: 如果你直接使用char数组来存储UTF-8编码的中文字符,你需要确保每个中文字符都正确地占用3个字节,并且在处理这些字符串时使用适合UTF-8的函数(如strlen,strcpy等),这样会失去一些宽字符带来的便利性,比如直接使用宽字符常量(如L'你')和宽字符串字面量(如L"你好")。
小编有话说
虽然C语言不是为处理Unicode而设计的,但通过合理地使用宽字符和相关库函数,我们仍然可以在C程序中有效地存储和处理中文字符,记得总是设置正确的区域设置,并在文件操作时指定正确的编码,以避免乱码问题,希望这篇指南能帮助你在C语言项目中顺利地集成中文支持!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/406013.html
相关文章
谷歌服务器如何设置中文?,如何在谷歌服务器上配置中文界面?,谷歌服务器语言设置中怎么添加中文?,谷歌服务器控制面板能切换到中文吗?,如何将谷歌服务器的语言修改为中文?,谷歌服务器管理控制台怎样选择简体中文?,在谷歌服务器设置中如何启用中文显示?,谷歌服务器支持哪些语言,如何设置为中文?,谷歌服务器后台管理可以调成中文吗?,10. 谷歌服务器有没有中文语言包或更新?,涵盖了用户可能对谷歌服务器设置中文的各种疑问和需求。
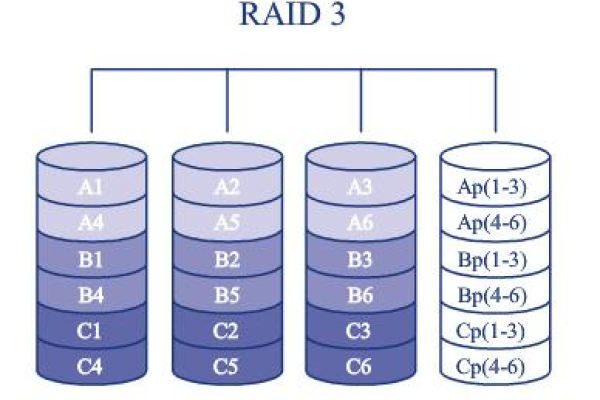
FC存储阵列是什么?它在数据存储中扮演什么角色?
如何在MySQL数据库中正确存储中文,并解决HiLens Kit显示中文问题?
注册中文域名,中文域名有必要注册吗2022年更新(注册中文域名,中文域名有必要注册吗2022年更新吗)
中文域名查询网址,中文域名查询(中文域名查询网址,中文域名查询不到)
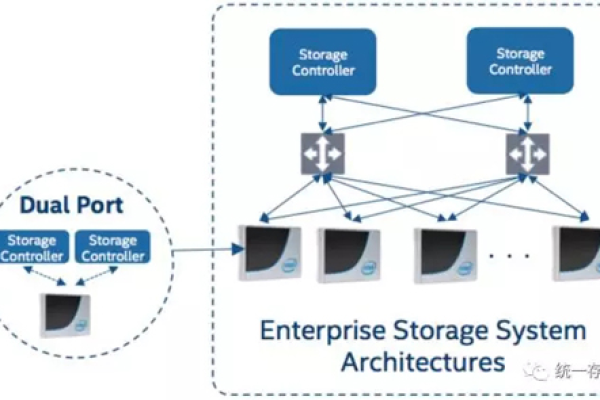
FC存储双链路,如何实现高效与稳定的数据存储?
FC存储相比NAS存储,成本差异何在?
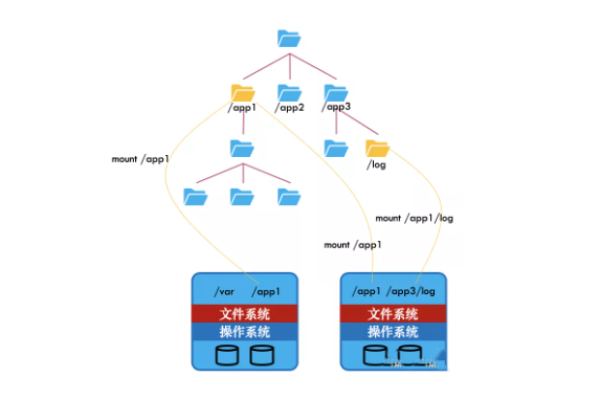
云存储中块存储与对象存储有何不同?








