
上一篇
curl 获取js跳转的页面
使用 curl 获取包含 JavaScript 跳转的页面时,由于 curl 是一个命令行工具,主要用于发送 HTTP 请求并获取响应内容,它本身无法执行 JavaScript 代码。如果目标页面通过 JavaScript 进行跳转(例如通过 window.location.href),curl 只能获取到原始的 HTML 内容,而无法自动跟随 JavaScript 跳转。要获取跳转后的页面内容,可以通过以下方式:1. **手动解析跳转 URL**:查看 curl 返回的 HTML 内容,找到 JavaScript 跳转的目标 URL,然后再次使用 curl 请求该 URL。, ,2. **使用浏览器工具**:通过浏览器开发者工具(如 Chrome DevTools)捕获跳转后的 URL,然后使用 curl 请求该 URL。3. **结合其他工具**:使用支持 JavaScript 渲染的工具(如 puppeteer 或 selenium)来模拟浏览器行为,获取跳转后的页面内容。curl 本身无法处理 JavaScript 跳转,需要结合其他方法或工具来获取最终页面内容。
curl获取JS跳转页面方法使用curl获取包含JavaScript跳转的网页内容,通常需要结合其他工具或技术。由于curl本身无法执行JavaScript,对于通过JavaScript实现的跳转,可先使用无头浏览器(如Puppeteer或Selenium)模拟浏览器行为,获取跳转后的URL或页面内容,再根据需求使用curl进行后续操作。
在网络数据采集领域,有时会遇到需要获取通过JavaScript跳转后的页面内容的情况,由于curl本身是一个命令行工具,主要用于发送HTTP请求,并不直接支持执行JavaScript代码,因此无法直接使用curl来获取JS跳转后的页面,不过,可以通过结合其他工具或方法来实现这一目标,以下是几种常见的解决方案:
1、使用无头浏览器
Puppeteer:这是一个Node库,提供了高级API来控制Chrome或Chromium浏览器,可以在无界面模式下运行它来处理页面跳转和动态内容加载。
Selenium:这是一个强大的工具,支持多种编程语言(如Python、Java、C#),可以自动化浏览器操作,处理页面跳转和动态内容。
2、利用API接口:有些网站提供API接口,可以直接获取数据而不需要解析JavaScript生成的内容,可以通过分析网络请求找到这些API接口,并使用cURL请求API。
3、解析JS文件:有时候可以通过解析JavaScript文件,找到生成内容的逻辑和数据源,这通常需要在浏览器的开发者工具中查找和分析JS文件。
4、结合无头浏览器和cURL:首先使用无头浏览器获取动态生成的链接,然后使用cURL下载内容。
FAQs
Q1: 如何使用cURL爬取包含JavaScript的链接?
A1: 使用cURL直接爬取包含JavaScript的链接是困难的,因为cURL本身不支持执行JavaScript代码,但可以结合无头浏览器(如Puppeteer或Selenium)来模拟浏览器行为,获取JavaScript执行后的页面内容,然后再使用cURL下载最终页面。
Q2: 如何让cURL执行JavaScript代码?
A2: cURL本身不能执行JavaScript代码,但可以通过结合第三方工具(如PhantomJS或Headless Chrome)来实现,这些工具可以模拟浏览器环境,执行JavaScript代码,并将结果返回给cURL。
小编有话说
在处理需要获取JS跳转后页面的任务时,选择合适的方法和工具至关重要,虽然cURL是一个强大的HTTP请求工具,但在面对JavaScript跳转时,我们需要借助其他工具或技术来实现目标,无论是使用无头浏览器、利用API接口、解析JS文件还是结合多种工具,关键在于理解页面的跳转机制和数据来源,也要遵守网站的robots.txt文件和使用条款,确保数据采集的合法性和道德性。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/406001.html
相关文章
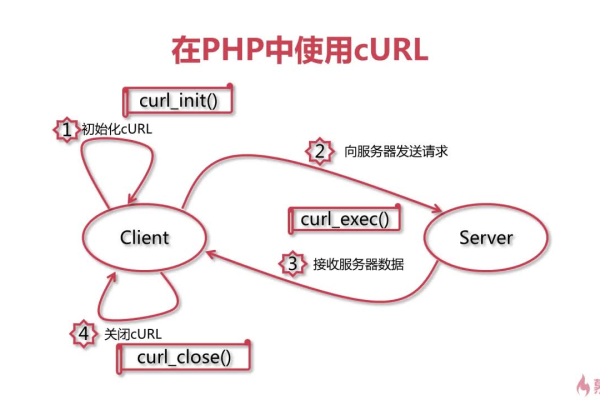
虚拟主机curl_curl 是一个关于使用 curl 命令与虚拟主机交互的教程或指南。基于这个主题,一个原创的疑问句标题可以是,,如何使用Curl在虚拟主机上进行高效数据传输?,不仅包含了文章的核心内容(使用Curl和虚拟主机),而且通过提问的方式激发了潜在读者的好奇心,促使他们点击阅读以获取答案。

动态url和静态url有什么区别,动态URL和静态URL有什么区别?
JS如何实现页面跳转?有哪些常用的JS跳转代码?
How to Activate the Circuit Breaker Protection Feature for Source Station Security in Information Security Level Protection?
html 如何跳转的页面居中
钉钉通过流程的回调事件是否可以获取到跳转的url?

开发工具curl互联网_curl
curl 镜像网站_curl








