
上一篇
csv 导入sql数据库 效率
本文探讨了将CSV文件导入SQL数据库时的效率问题,包括不同方法的比较和优化技巧。
将CSV文件导入SQL数据库是一项常见的数据迁移任务,但在处理大量数据时,效率成为一个关键因素,以下是一些提高CSV导入SQL数据库效率的方法:

1. 使用批量插入(Batch Insert)
方法描述:
批量插入是将多个记录一次性插入到数据库中,而不是逐条插入,这可以减少网络往返次数和事务开销,从而提高效率。
示例代码(Python + SQLite):
import csv
import sqlite3
连接到SQLite数据库
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS users (id INTEGER PRIMARY KEY, name TEXT, age INTEGER)''')
读取CSV文件
with open('users.csv', 'r') as file:
reader = csv.reader(file)
next(reader) 跳过标题行
rows = [row for row in reader]
批量插入数据
batch_size = 1000 设置批处理大小
for i in range(0, len(rows), batch_size):
batch = rows[i:i + batch_size]
query = "INSERT INTO users (name, age) VALUES (?, ?)"
cursor.executemany(query, batch)
conn.commit()
conn.close()优点:
减少数据库交互次数。
提高插入速度。
缺点:
需要更多的内存来存储批量数据。
错误处理更复杂。
使用数据库特定的工具和命令
方法描述:
许多数据库系统提供了专门的工具和命令来高效地导入CSV数据,如MySQL的LOAD DATA INFILE命令。
示例代码(MySQL):
LOAD DATA INFILE '/path/to/users.csv' INTO TABLE users FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY ' ' IGNORE 1 ROWS;
优点:
专为大数据量设计,效率高。
简单易用。
缺点:
特定于数据库系统,不具有通用性。
可能需要额外的权限配置。
优化数据库配置
方法描述:
调整数据库的配置参数可以显著提高导入效率,如增加缓存大小、调整写入策略等。
示例(MySQL配置调整):
[mysqld] innodb_buffer_pool_size = 2G innodb_log_file_size = 512M innodb_flush_log_at_trx_commit = 2
优点:
提升整体数据库性能。
适用于大规模数据处理。
缺点:
需要重启数据库服务。
可能需要根据硬件资源进行调整。
使用多线程或异步处理
方法描述:
通过多线程或异步编程技术,可以并行处理多个CSV文件或文件中的不同部分,从而提高整体导入速度。
示例代码(Python + concurrent.futures):
from concurrent.futures import ThreadPoolExecutor
import csv
import sqlite3
def import_csv(file_path):
with open(file_path, 'r') as file:
reader = csv.reader(file)
next(reader) 跳过标题行
rows = [row for row in reader]
这里添加批量插入逻辑...
files = ['file1.csv', 'file2.csv', 'file3.csv']
with ThreadPoolExecutor(max_workers=4) as executor:
executor.map(import_csv, files)优点:
充分利用多核CPU资源。
加快处理速度。
缺点:
需要处理线程同步和冲突问题。
增加代码复杂度。
预处理和索引优化
方法描述:
在导入前对CSV数据进行预处理,如排序、去重,以及在导入后创建合适的索引,都可以提高查询效率。
示例代码(创建索引):
CREATE INDEX idx_user_age ON users (age);
优点:
提高后续查询效率。
优化数据结构。
缺点:
创建索引可能会增加写入时间。
需要额外的存储空间。
使用ETL工具
方法描述:
ETL(Extract, Transform, Load)工具如Apache NiFi、Talend等,提供了图形化界面和强大的数据处理能力,适合复杂的数据转换和加载任务。
优点:
易于使用和维护。
支持多种数据源和目标。
提供丰富的数据处理功能。
缺点:
学习曲线较陡。
可能需要付费或开源许可限制。
监控和调优
方法描述:
在导入过程中实时监控数据库性能指标,如CPU使用率、内存占用、磁盘I/O等,并根据监控结果进行调优。
优点:
及时发现并解决问题。
确保系统稳定运行。
缺点:
需要专业的监控工具和技能。
增加了操作复杂性。
分阶段导入和验证
方法描述:
将大型CSV文件分割成多个小文件分阶段导入,并在每个阶段后进行数据验证,确保数据完整性和准确性。
示例流程:
1、分割CSV文件为多个小文件。
2、导入第一个小文件并验证。
3、重复步骤2直到所有文件导入完成。
4、最后进行全面的数据校验。
优点:
降低单次导入失败的风险。
便于逐步调试和验证。
缺点:
增加了额外的分割和合并步骤。
可能需要编写额外的脚本或程序。
9. 使用内存映射文件(Memory-Mapped Files)
方法描述:
对于非常大的CSV文件,可以使用内存映射文件技术,将文件内容映射到进程的地址空间,从而实现高效的文件读写操作。
示例代码(Python + mmap):
import mmap
import csv
import os
import sqlite3
def read_large_csv(file_path):
with open(file_path, 'r+b') as f:
mmapped_file = mmap.mmap(f.fileno(), length=0, access=mmap.ACCESS_READ)
return mmapped_file.read().decode('utf-8').splitlines()
假设已经有一个函数来处理CSV行并插入数据库...
process_and_insert(line)优点:
高效处理大文件,减少内存占用。
提高文件I/O性能。
缺点:
实现较为复杂。
需要处理文件编码和换行符等问题。
10. 考虑使用NoSQL数据库或分布式数据库系统
方法描述:
对于超大规模的数据导入任务,传统的关系型数据库可能不是最佳选择,此时可以考虑使用NoSQL数据库(如MongoDB、Cassandra)或分布式数据库系统(如Hadoop、Spark),它们通常能够更好地处理海量数据和高并发场景。
优点:
横向扩展能力强。
适合处理非结构化或半结构化数据。
提供高性能的数据存储和查询能力。
缺点:
数据模型与传统关系型数据库不同,可能需要重新设计数据结构。
学习和使用成本较高。
生态系统和工具支持可能不如传统关系型数据库成熟。
FAQs:
1、Q: 如果CSV文件非常大,内存不足以一次性加载所有数据,应该怎么办?
A: 可以将CSV文件分割成多个较小的文件,然后逐个导入,或者使用流式处理的方式,逐行读取并插入数据库,避免一次性加载过多数据到内存中。
2、Q: 如何确保CSV导入过程中数据的一致性和完整性?
A: 可以在导入前后进行数据校验,比如检查记录数、计算哈希值等,使用事务管理确保要么全部成功要么全部回滚,避免部分数据导入导致的数据不一致问题,合理设置数据库的约束条件(如外键、唯一性约束)也有助于保证数据的完整性。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/402516.html
相关文章
-
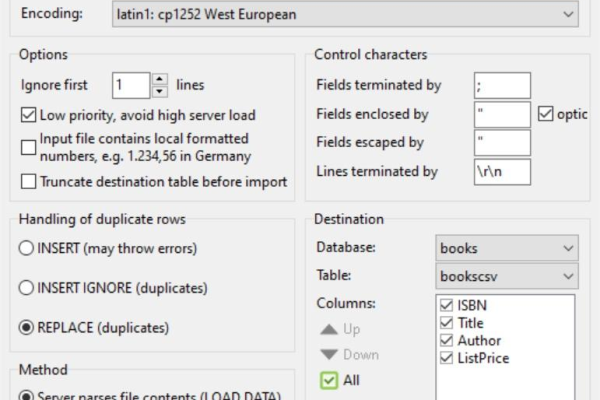
csv文件导入mysql数据库_CSV文件输入
-

苹果6手机将通讯录全部导入sim卡 苹果6手机通讯录导入SIM卡
-

以下几个疑问句标题可供选择,,如何查看 RDS for MySQL 数据库死锁日志及 MySQL 表格字段相关问题解析,RDS for MySQL 死锁日志怎么查看?与 MySQL 表格字段操作探讨,怎样查看 RDS for MySQL 数据库的死锁日志?关于 MySQL 表格字段的思考,RDS for MySQL 数据库死锁日志查看方法与 MySQL 表格字段研究,如何查看 RDS for MySQL 数据库死锁日志?对 MySQL 表格字段的分析
-
mysql数据库代码_Mysql数据库这篇文章可能涉及MySQL数据库的编程、管理或优化等方面的内容。根据这些信息,我们可以为文章生成一个原创的疑问句标题,例如,,如何编写高效的MySQL数据库代码以提升性能?,不仅提出了一个问题,而且暗示了文章内容可能包含关于编写高效MySQL代码和提升数据库性能的技巧与建议。
-
导入txt数据到mysql数据库中_从OBS导入CSV,TXT数据
-
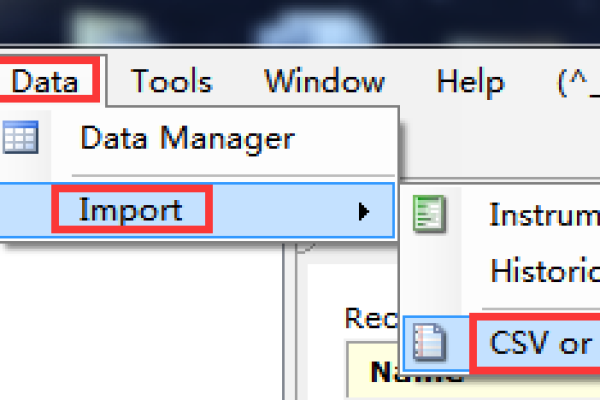
导入csv文件给数据库_CSV文件输入
-
csv存入mysql数据库_CSV Format
-
csv mysql数据库中_CSV Format
-
为什么MySQL数据库在导入SQL格式数据时需要确保与MySQL模式兼容?








