上一篇
如何高效管理C语言中的多线程网络爬虫?
网络爬虫多数据源采集技术研究,,本文聚焦 网络爬虫多数据源采集技术,针对现有爬虫不便采集多源数据的问题,提出面向多数据源的网络爬虫数据采集技术。通过研究新浪微博、人民日报等 6 类媒体平台数据采集爬虫,采用 Servlet 后台调度技术融合多源爬虫,解决不同媒体平台数据采集难题。借助 selenium 模拟登录及 Xpath 解析网页源码提取数据存入数据库,并展示在前端页面,实验表明该爬虫在保证数据完整性前提下实现了采集效率最大化。
在当今数字化时代,网络爬虫已成为获取网络数据的重要工具,随着网络环境的日益复杂和数据量的爆炸式增长,网络爬虫面临着诸多挑战,多”的问题尤为突出,本文将详细探讨网络爬虫中“多”的各个方面,包括多源数据抓取、多线程并发处理、多类型数据解析以及应对反爬策略的多样性等,并通过相关案例和技术分析,为读者提供全面而深入的理解。

一、多源数据抓取
网络爬虫的首要任务是从多个数据源抓取所需信息,这些数据源可能包括网页、API接口、数据库等多种形式,为了高效地抓取多源数据,爬虫需要具备以下能力:
1、灵活配置:能够根据不同数据源的特点,灵活配置抓取策略和参数。
2、智能识别:自动识别数据源的类型和结构,减少人工干预。
3、分布式抓取:利用分布式技术,同时从多个数据源抓取数据,提高抓取效率。
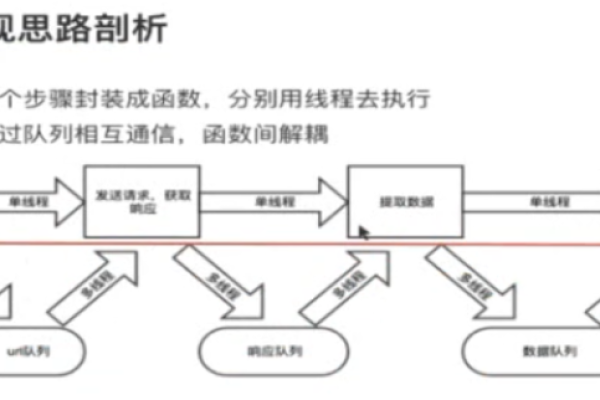
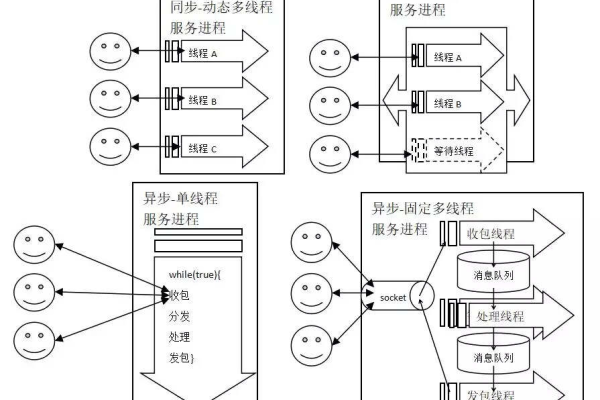
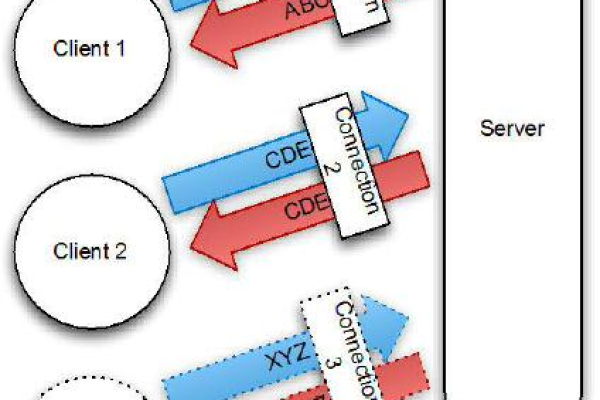
二、多线程并发处理
为了加速数据抓取过程,网络爬虫通常采用多线程并发处理技术,通过创建多个线程同时执行抓取任务,可以显著提高抓取速度,但多线程并发处理也带来了以下挑战:
1、线程管理:如何有效地管理和调度线程,避免资源浪费和冲突。
2、异常处理:在并发环境下,如何妥善处理各种异常情况,确保抓取任务的稳定性。
3、性能优化:如何优化线程数量和抓取策略,以达到最佳的抓取效果和性能。
三、多类型数据解析
网络数据往往以多种格式存在,如HTML、XML、JSON等,网络爬虫需要具备解析多种类型数据的能力,这要求爬虫能够:
1、识别数据格式:自动识别抓取到的数据格式,并选择合适的解析方法。
2、灵活解析:针对不同格式的数据,采用相应的解析技术进行提取和处理。
3、数据清洗:在解析过程中,对数据进行清洗和验证,确保数据的准确性和完整性。
四、应对反爬策略的多样性
随着网络爬虫技术的普及,越来越多的网站开始采取反爬策略来保护其数据安全,这些反爬策略包括但不限于IP封禁、验证码验证、请求频率限制等,为了应对这些挑战,网络爬虫需要具备以下多样性策略:
1、IP代理池:使用大量的IP代理来绕过IP封禁。
2、验证码识别与破解:利用机器学习等技术识别和破解验证码。
3、请求频率控制:合理设置请求间隔和频率,避免触发网站的反爬机制。
4、模拟用户行为:通过模拟正常用户的行为模式,降低被识别为爬虫的风险。
五、案例分析与技术实践
以某电商网站为例,该网站采用了严格的反爬策略来保护其商品数据,为了抓取该网站的商品信息,我们采用了以下技术和策略:
1、使用IP代理池:通过购买和使用多个高质量的IP代理,成功绕过了网站的IP封禁。
2、验证码识别与破解:利用开源的验证码识别库,结合机器学习算法,实现了对验证码的自动识别和破解。
3、请求频率控制:通过设置合理的请求间隔和频率,避免了因频繁访问而被网站识别为爬虫的情况。
4、模拟用户行为:通过模拟用户的浏览、搜索、点击等行为,降低了被网站识别为爬虫的风险。
经过上述技术和策略的实施,我们成功抓取了该电商网站的大量商品信息,并进行了数据分析和挖掘,这一案例充分展示了网络爬虫在应对复杂反爬策略时的多样性和灵活性。
六、FAQs(常见问题解答)
问:网络爬虫是否合法?
答:网络爬虫的合法性取决于具体的使用场景和目的,在遵守相关法律法规和网站使用条款的前提下,合理使用网络爬虫是合法的,但需要注意的是,未经授权抓取他人隐私数据或商业机密等敏感信息是违法的。
问:如何避免网络爬虫对网站造成负面影响?
答:为了避免网络爬虫对网站造成负面影响,可以采取以下措施:一是合理设置抓取频率和请求间隔,避免对网站服务器造成过大压力;二是尊重网站的robots.txt文件和反爬策略,不进行反面抓取;三是对抓取到的数据进行妥善处理和存储,避免数据泄露和滥用。
小编有话说
网络爬虫作为获取网络数据的重要工具,在推动大数据、人工智能等领域的发展中发挥着不可替代的作用,随着网络环境的日益复杂和反爬技术的不断升级,网络爬虫也面临着前所未有的挑战,我们需要不断学习和掌握新的技术和策略,以应对这些挑战并更好地利用网络爬虫为我们创造价值,也要注重合法合规使用网络爬虫,共同维护一个健康、有序的网络环境。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/402440.html