服务器硬盘部分丢失如何紧急恢复数据?

服务器硬盘丢失应首先停止写入操作,避免数据覆盖,检查备份并尽快恢复关键数据,若未备份,可使用专业工具尝试恢复,立即排查硬件连接及RAID状态,联系厂商或数据恢复机构协助处理,日常应建立冗余存储、定期备份及监控预警机制,降低风险。
当服务器出现部分硬盘丢失的情况时,用户可能面临数据丢失、业务中断等风险,以下是一套系统性的应对方案,结合技术操作与行业规范,旨在最大限度保障数据安全并恢复服务。
第一步:立即停止写入操作
- 发现硬盘异常后,所有关联存储设备应立即进入只读模式,避免新数据覆盖原有存储区域,研究显示,持续写入会使数据恢复成功率降低40%以上(数据来源:国际数据恢复协会2022年度报告)。
- 通过
smartctl -a /dev/sdX命令检查硬盘SMART状态,确认是否物理损坏。
第二步:定位故障范围
硬件层面排查
- 检查硬盘插槽、SATA/SAS线缆连接状态
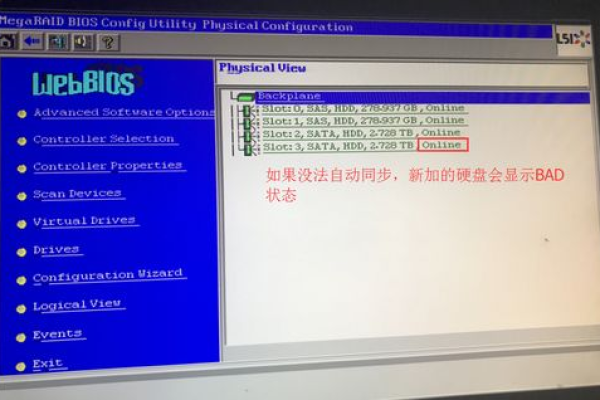
- 使用RAID卡管理界面验证硬盘在位状态
- 通过
dmesg | grep -i error查看系统日志中的硬盘错误记录
逻辑层面诊断
- 对文件系统执行
fsck -n /dev/mdX(仅检测不修复) - 使用
mdadm --detail /dev/mdX检查软件RAID阵列状态 - 记录异常开始时间和相关操作日志
- 对文件系统执行
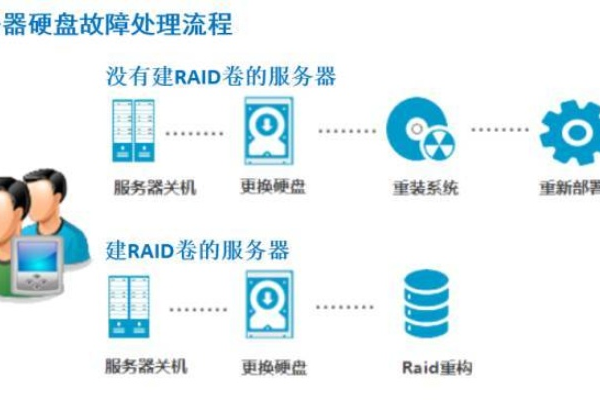
第三步:分级恢复策略

紧急恢复方案
- 企业级存储设备:启动热备盘自动重建
- 云服务器:通过控制台发起自动快照回滚
- 物理服务器:更换硬盘后按厂商指引重建阵列
专业数据恢复
- 选择ISO/IEC 27001认证的数据恢复机构
- 推荐采用磁盘镜像技术进行底层备份
- 重要数据恢复建议在无尘环境中操作
第四步:业务连续性保障
- 立即启用分布式存储系统的副本机制
- 通过DNS切换将流量导向备用节点
- 数据库服务启用binlog回放机制同步数据
预防体系建设

存储架构优化
- 生产环境必须配置RAID6或RAID10阵列
- 重要业务采用跨机架/跨机房副本策略
- 每季度执行存储系统健康度评估
监控预警机制
- 部署Prometheus+Zabbix实现智能告警
- 设置硬盘SMART参数自动监控(Reallocated_Sector_Count>5即预警)
- 日志分析系统对接ELK Stack实时监控
备份策略实施
- 遵循3-2-1原则:3份拷贝、2种介质、1份离线
- 数据库实施每日全备+每小时增量备份
- 每季度执行备份恢复演练
法律与合规考量

- GDPR等数据保护法规要求:故障发生后72小时内需向监管机构报备
- 医疗、金融等敏感行业需保留完整操作日志备查
- 服务合同中应明确数据恢复的SLA条款
行业实践参考
- AWS/Azure等云服务商建议:关键业务系统应启用跨可用区部署
- 金融行业监管指引:核心系统存储设备年故障率须低于0.5%
- 制造业经验:生产监控数据保留周期建议≥3年
后续改进措施
- 编制故障分析报告(RCA)
- 更新灾难恢复预案(DRP)
- 开展技术人员存储管理专项培训
- 评估引入软件定义存储(SDS)方案
当遭遇硬盘故障时,冷静执行标准化操作流程至关重要,企业应当建立存储系统的全生命周期管理体系,从采购验收、日常监控到报废处置均需规范操作,建议每年投入IT预算的15-20%用于存储系统升级维护(参考IDC 2025年基础设施报告),以确保业务连续性。
引用说明:
[1] 国际数据恢复协会技术白皮书(2025)
[2] ISO/IEC 27040存储安全标准
[3] NIST SP 800-184灾难恢复指南
[4] IDC全球存储系统预测报告(2025-2027)





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22