上一篇
如何优化分布式存储系统中的节点冗余以提高数据可靠性?
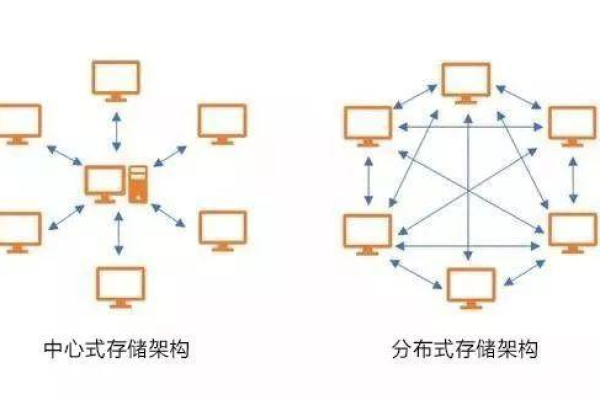
分布式存储通过多节点冗余,提高数据可靠性与访问速度。各节点间同步复制数据,确保单点故障不影响整体系统运行。
在分布式存储系统中,节点冗余是确保数据可靠性和系统高可用性的关键策略之一,通过在不同的物理位置或网络中部署多个存储节点,即使部分节点发生故障,系统仍然能够继续运行并提供数据访问服务,这种设计不仅提高了系统的容错能力,还增强了对数据丢失或损坏的防护。

一、节点冗余的重要性
提高数据可靠性:通过在不同地理位置分布存储节点,即使某个地区遭受自然灾害或其他不可预见的事件,其他节点上的数据副本仍然可以保证数据的完整性和可访问性。
增强系统可用性:当一个或多个节点由于硬件故障、软件错误或维护操作而暂时不可用时,其他健康节点可以无缝接管,确保服务的连续性。
优化性能与延迟:将数据存储在离用户更近的位置可以减少访问延迟,提升用户体验,多节点并行处理也能加快数据处理速度,特别是在大数据分析和机器学习等场景下尤为重要。
二、实现方式
1. 复制(Replication)
同步复制:所有副本同时更新,适用于对一致性要求极高的场景。
异步复制:主节点首先完成写操作,然后异步地将变更传播到从节点,适用于需要较高吞吐量但对实时性要求不高的应用。
2. 纠删编码(Erasure Coding)
通过复杂的数学算法将原始数据分割成多个片段,并加入额外的校验信息,即使丢失了一部分片段,也能利用剩余片段重建原始数据,这种方法相比简单复制节省了存储空间,但增加了计算复杂度。
3. 多活架构(Multi-Active Architecture)
在这种模式下,每个节点都处于活动状态且具备读写能力,客户端请求可以根据负载均衡策略动态分配给任何一个可用节点,进一步提高了系统的灵活性和响应速度。
三、挑战与解决方案
一致性问题:在分布式环境中保持数据一致性是一个难题,采用合适的一致性模型如强一致性、最终一致性等,并结合CAP定理指导设计决策。
网络延迟与带宽限制:合理规划数据中心布局,使用CDN加速内容分发;对于跨地域通信,考虑引入边缘计算技术减少核心网负担。
成本控制:虽然增加冗余可以提高安全性,但也意味着更高的硬件投入及运维成本,在设计时应综合考量业务需求与预算限制,寻找最佳平衡点。
四、实践案例分析
| 案例名称 | 使用技术 | 成果 |
| Hadoop HDFS | 数据块复制 | 实现了大规模数据集的高效管理和快速恢复能力 |
| Ceph | CRUSH算法+纠删编码 | 提供了高度灵活的存储池配置选项以及优秀的扩展性 |
| Amazon S3 | 多区域复制+版本控制 | 确保全球范围内用户都能获得低延迟访问体验的同时保障数据安全 |
五、相关问答FAQs
Q1: 如何选择合适的冗余级别?
A1: 选择冗余级别需考虑因素包括但不限于数据重要性、预期故障率、恢复时间目标(RTO)和服务级别协议(SLA)要求等,对于关键业务数据建议采用至少两份副本;而对于非敏感信息,则可根据实际情况适当降低冗余度以节约成本。
Q2: 纠删编码与简单复制相比有哪些优势?
A2: 纠删编码的主要优势在于它能够在相同容量条件下提供更多的有效存储空间利用率,使用(k,m)编码方案时,只需存储k个数据块加上m个校验块即可保护整个数据集不受单点故障影响,相比之下,简单复制则需要为每份数据创建完整的副本,这显然会占用更多磁盘资源,纠删编码还能更好地抵御随机错误而非仅限于完全失效的情况。
小编有话说
随着云计算技术的发展以及企业数字化转型步伐加快,构建健壮可靠的分布式存储解决方案变得越来越重要,希望本文能够帮助大家更好地理解节点冗余的概念及其应用场景,为企业IT架构设计提供参考依据,如果您有任何疑问或者想要了解更多相关信息,请随时留言交流!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/379427.html