
上一篇
如何使用Spark小文件合并工具来合并MDB数据库?
使用Spark小文件合并工具时,请确保当前用户对表具有owner权限,并保证HDFS上有足够的存储空间。合并过程中需单独进行表数据操作,避免写操作以维护数据一致性。
使用Spark小文件合并工具可以有效解决在数据处理过程中遇到的小文件问题,提高数据处理效率和存储管理便捷性,以下是详细的步骤说明:

一、设置Spark配置参数
在使用Spark进行小文件合并之前,需要先设置一些关键的配置参数,以优化合并过程,这些参数包括每个分区的最大字节数和最小分区数量等,具体操作如下:
from pyspark.sql import SparkSession
import org.apache.spark.SparkConf
创建Spark配置对象
sparkConf = new SparkConf()
.setAppName("Small File Merge Example")
.set("spark.sql.files.maxPartitionBytes", "134217728")
.set("spark.sql.files.minPartitionNum", "10")
创建SparkSession
spark = SparkSession.builder().config(sparkConf).getOrCreate()二、读取小文件数据
需要读取存储在HDFS或本地文件系统中的小文件,这里假设文件格式为CSV。
读取小文件数据
smallFilesDF = spark.read
.option("header", "true")
.csv("hdfs://path/to/small/files/*")
打印Schema,确认数据正确读取
smallFilesDF.printSchema()三、合并小文件
读取小文件后,可以使用coalesce或repartition方法进行合并操作,这里推荐使用coalesce,因为它在合并时能保持分区数量较低,从而减小Shuffle的开销。
合并小文件
mergedDF = smallFilesDF.coalesce(5) # 根据需要的分区数量进行重分区
验证合并后的数据
print(f"合并后数据的分区数量: {mergedDF.rdd.getNumPartitions()}")四、保存合并后的数据
将合并后的数据保存到指定的输出路径,可以选择不同的格式,这里以CSV为例。
保存合并后的数据
mergedDF.write
.mode("overwrite")
.option("header", "true")
.csv("hdfs://path/to/output/merged_file.csv")
显示保存成功的信息
print("合并后的数据已成功保存!")五、验证数据合并结果
检查合并后的数据是否符合预期。
读取合并后的数据进行验证
dfVerification = spark.read.csv("hdfs://path/to/output/merged_file.csv", header=True, inferSchema=True)
显示合并后的数据
dfVerification.show()通过以上步骤,可以有效地使用Spark SQL小文件合并工具来处理小文件问题,提高数据处理的效率和性能。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/379120.html
相关文章
-
如何使用Spark小文件合并工具来合并MySQL多数据库?
-
如何使用Spark小文件合并工具来整合MySQL数据库表?
-
如何有效使用Spark小文件合并工具进行MySQL数据库表的合并?
-
如何有效利用Spark小文件合并工具进行MySQL多数据库整合?
-
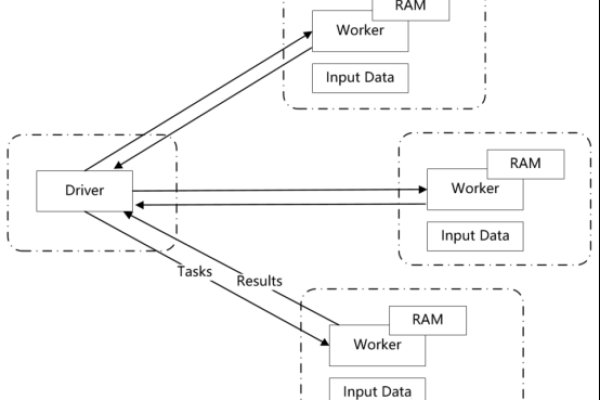
在分布式计算领域,MapReduce和Spark作为两种流行的大数据处理框架,它们在设计哲学、性能优化以及易用性方面存在显著差异。特别是当涉及到华为云的DLI(数据湖探索)服务中的Spark组件与华为云MRS(MapReduce服务)中的Spark组件时,用户可能会好奇这两者之间的具体区别是什么?
-
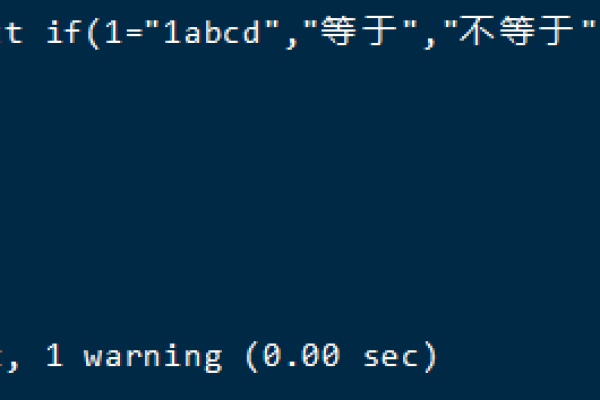
在编写关于MySQL和Spark SQL中ROLLUP与CUBE操作的注意事项时,一个原创的疑问句标题可以是,,在使用MySQL和Spark SQL进行数据聚合时,如何正确应用ROLLUP和CUBE功能以避免常见错误?
-

vba按合并单元格拆分工作簿 wps合并工具?
-
如何使用ASP技术访问MDB数据库?








