上一篇
分布式存储中的副本概念是什么?
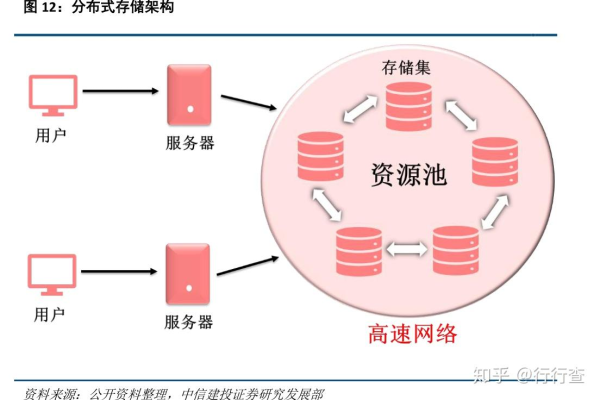
分布式存储的副本指的是在多个节点上保存同一份数据的多个拷贝,用于提高系统的可靠性和可用性。
分布式存储系统中的副本(Replica)是指数据的多个拷贝,这些拷贝分布在不同的节点上,副本的主要目的是提高系统的可靠性和可用性,以下是关于副本的一些关键概念和用途的详细解释:

一、副本的概念
1、数据冗余:通过在多个节点上存储相同的数据,即使某个节点发生故障,数据仍然可用,这提高了数据的可靠性和系统的容错能力。
2、负载均衡:通过在多个节点上分布读请求,减少单个节点的压力,提高系统的整体性能,这有助于提升系统的吞吐量和响应速度。
3、高可用性:确保在某些节点失效的情况下,系统仍然可以正常运行,这减少了服务中断的时间,提高了用户体验。
二、副本的工作原理
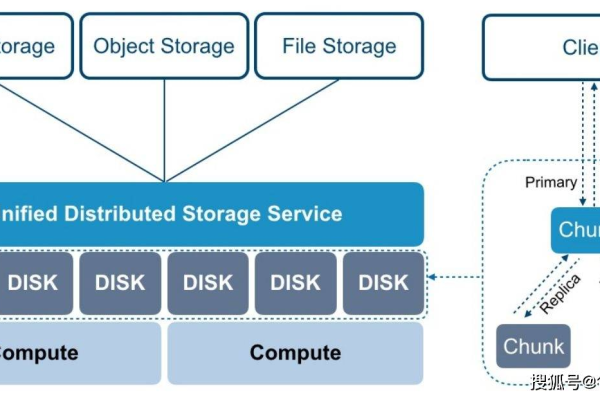
1、主副本(Leader Replica):在一个分区(Partition)中,通常会有一个主副本,负责接收写请求并协调数据的一致性,主副本将写操作的结果同步到其他副本,并确保所有副本的数据保持一致。
2、从副本(Follower Replica):除了主副本之外的其他副本称为从副本,从副本接收主副本发送的数据更新,并保持数据的一致性,从副本可以处理读请求,减轻主副本的负担。
三、副本的管理和维护
1、副本同步:主副本将写操作的结果同步到从副本,确保所有副本的数据保持一致,通常使用一致性协议(如Raft或Paxos)来保证数据的一致性。
2、故障恢复:当主副本失效时,系统会选择一个从副本作为新的主副本,继续处理写请求,这通常通过选举机制来实现。
四、副本的示例
假设你有一个Kudu表,其分区信息如下:
| # Rows | Start Key | Stop Key | Leader Replica | # Replicas |
| 1000 | NULL | NULL | node1 | 3 |
| 2000 | NULL | NULL | node2 | 3 |
在这个例子中:
# Replicas列显示每个分区有3个副本。
Leader Replica列显示每个分区的主副本所在的节点,第一个分区的主副本在node1上,第二个分区的主副本在node2上。
五、副本的优缺点分析
1. 优点
高可用性:即使部分节点失效,系统仍然可以正常运行,因为数据在其他节点上有备份。
负载均衡:读请求可以分散到多个节点,减轻单个节点的压力。
数据保护:多副本机制可以防止数据丢失,提高数据的可靠性。
2. 缺点
存储成本增加:需要额外的存储空间来保存数据的多个副本。
一致性问题:在分布式环境中,确保所有副本的数据一致性是一个挑战,尤其是在网络延迟或节点故障的情况下。
管理复杂性:需要复杂的管理机制来创建、维护和删除副本,以及处理故障恢复。
六、副本与纠删码的比较
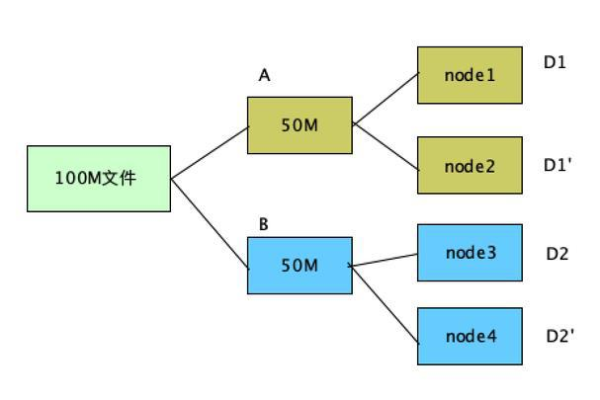
1、多副本技术:通过复制数据到多个节点来提供冗余,优点是实现简单,缺点是存储效率较低,因为需要额外的存储空间来保存多个完整的数据副本。
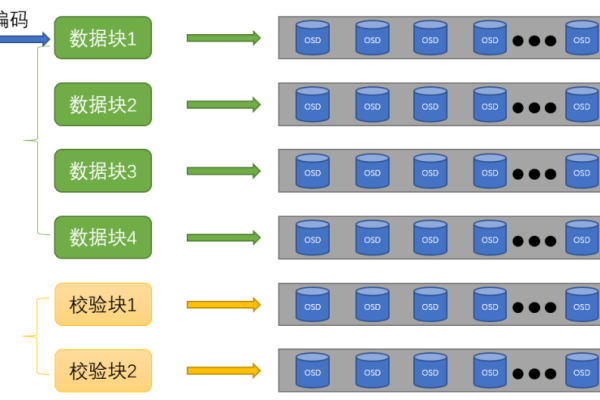
2、纠删码技术:通过编码技术将数据切分成多个分片,并生成校验分片,优点是存储效率较高,可以在相同存储空间内提供更高的数据冗余,缺点是计算复杂度较高,需要额外的计算资源来生成和重建数据。
分布式存储系统中的副本机制通过在多个节点上存储数据的多个拷贝,提高了系统的可靠性、可用性和性能,这也带来了存储成本增加和管理复杂性的挑战,在选择副本数量和管理策略时,需要在数据冗余和系统性能之间进行权衡。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/378840.html