
上一篇
分布式存储计算架构,它如何改变我们的数据处理方式?
分布式存储计算架构是一种将数据和计算任务分散在多个节点上的系统设计,以提高数据处理效率、可靠性和可扩展性。
分布式存储计算架构是一种先进的数据存储和处理方式,它将数据分散存储在多个计算机或服务器上,通过分布式计算技术实现数据的高效处理和存储,以下将从分布式存储计算架构的基本原理、关键技术、优缺点以及应用场景等方面进行详细阐述。

一、分布式存储计算架构的基本原理
1. 数据分片与副本复制
数据分片:在分布式存储系统中,数据被分成多个部分,每个部分存储在不同的节点上,以实现数据的分布式存储和管理,数据分片通常使用哈希函数或一致性哈希算法来实现,确保数据均匀分布在各个节点上。
副本复制:为了提高数据的可靠性和可用性,分布式存储系统通常使用副本复制技术,每个数据副本都存储在不同的节点上,以确保即使某些节点出现故障,仍然可以从其他节点中恢复数据,副本复制通常使用复制策略来实现,例如简单的复制、多副本复制和跨区域复制等。
2. 数据一致性
在分布式存储系统中,数据一致性是非常重要的,为了确保数据在不同节点之间的一致性,分布式存储系统通常使用数据同步和管理机制,使用Paxos算法、Raft算法或ZooKeeper等分布式协调服务来实现数据同步和管理。
3. 数据访问
在分布式存储系统中,数据可以并行地从多个节点中读取和写入,以提高读写性能和吞吐量,数据访问通常使用负载均衡机制来实现,例如使用分布式哈希表、分布式缓存或分布式文件系统等技术来实现。
二、分布式存储计算架构的关键技术
1. 分布式文件系统
分布式文件系统通过将数据分布存储在多个节点上,并提供统一的访问接口,使用户可以像访问本地文件系统一样访问分布式存储的数据,常见的分布式文件系统有Hadoop分布式文件系统(HDFS)、GlusterFS、Ceph等。
2. 分布式对象存储
对象存储主要通过对象来组织数据,每个对象包含数据本身及其元数据,适合于非结构化数据的存储,典型的分布式对象存储系统有Amazon S3、MinIO、Ceph对象存储等。
3. 数据分片与哈希分布
在分布式存储系统中,数据通常通过分片和哈希分布的方式进行管理,分片(Sharding)将数据划分为多个小块并分布存储在不同的节点上,通过一致性哈希或其他分布策略来定位数据的位置。
4. 冗余技术
冗余设计是提升分布式存储系统可靠性的关键手段,常见的冗余技术包括数据副本、纠删码(Erasure Coding)、数据快照等,数据副本是最常用的冗余方式,将同一数据复制多份,分别存储在不同节点上,纠删码则是一种更为节省存储空间的冗余方式,通过一定的算法计算出校验块,即使部分数据块丢失,也可以通过校验块还原数据。
三、分布式存储计算架构的优缺点
1. 优点
可靠性高:由于数据存储在多个节点上,即使某些节点出现故障,仍然可以从其他节点中恢复数据,从而提高了数据的可靠性和可用性。
扩展性好:分布式存储可以通过增加存储节点来扩展存储容量,因此可以轻松地扩展存储系统的规模和容量。
性能高:由于数据可以并行地从多个节点中读取和写入,因此分布式存储可以提供更高的读写性能和吞吐量。
灵活性强:分布式存储可以根据应用程序的需求进行配置和调整,以满足不同的数据存储和访问需求。
成本低:相比于传统的中心化存储系统,分布式存储可以使用通用的硬件和软件,因此成本更低。
2. 缺点
系统复杂性高:分布式存储需要在多个节点之间进行数据同步和管理,因此系统的复杂性较高,需要更多的管理和维护工作。
数据一致性问题:由于数据存储在多个节点上,因此需要确保数据在不同节点之间的一致性,在进行数据同步和管理时,可能会出现数据不一致的问题,从而影响系统的可靠性和性能。
数据安全性问题:在分布式存储中,数据存储在多个节点上,因此需要确保数据的安全性,如果某个节点存在安全破绽或被攻击,则可能会导致数据泄露或丢失。
系统性能下降:在进行数据同步和管理时,分布式存储可能会导致系统性能下降,在进行数据备份和恢复时,需要从多个节点中读取和写入数据,这会导致系统的响应时间和吞吐量下降。
四、应用场景
大数据处理:分布式存储计算架构适用于大规模数据的处理和分析,如日志分析、数据挖掘、机器学习等场景。
云计算服务:在云计算环境中,分布式存储计算架构可以提供弹性、可扩展的存储资源,满足各种应用的需求。
内容分发网络(CDN):CDN利用分布式存储计算架构将内容缓存到离用户更近的节点上,提高内容的访问速度和用户体验。
物联网(IoT):在物联网应用中,分布式存储计算架构可以处理来自大量传感器和设备的数据,实现实时监控和数据分析。
五、FAQs
Q1: 如何选择适合的分布式存储系统?
A1: 选择适合的分布式存储系统需要考虑数据类型、访问模式、可用性、扩展性、性能、一致性、安全性以及成本等因素,根据具体需求选择合适的系统和技术方案。
Q2: 分布式存储如何处理大数据?
A2: 分布式存储通过数据分片、副本复制、负载均衡以及数据压缩和优化等技术来处理大数据,这些技术可以确保数据的可靠性、可用性和高性能。
Q3: 分布式存储如何保证数据一致性?
A3: 分布式存储通常使用一致性协议(如Paxos、Raft等)和副本写入策略来保证数据一致性,这些机制可以确保不同节点上的数据副本保持一致。
Q4: 分布式存储如何处理数据冗余?
A4: 分布式存储通过数据副本、纠删码、数据分区以及数据多副本等技术来处理数据冗余,这些技术可以提高数据的容错性和可靠性。
六、小编有话说
随着大数据和云计算技术的不断发展,分布式存储计算架构已经成为现代数据存储和处理的主流方案,它通过将数据分散存储在多个节点上,实现了数据的高可靠性、可扩展性和高性能,分布式存储计算架构也面临着系统复杂性高、数据一致性和安全性等问题,在选择和使用分布式存储计算架构时,需要根据具体需求进行综合考虑和权衡,随着技术的不断进步和完善,相信分布式存储计算架构将会在未来发挥更加重要的作用。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/378518.html
相关文章
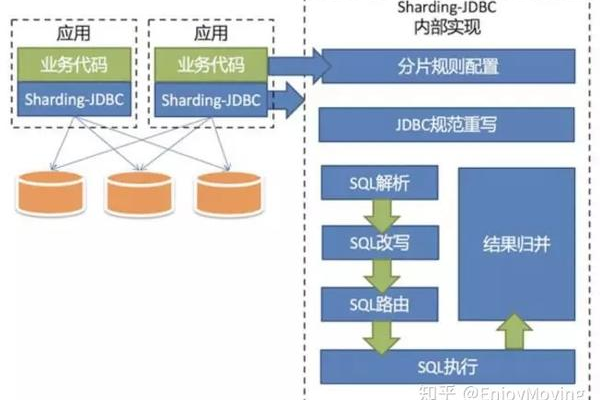
什么是分布式存储,它如何改变我们的数据处理方式?
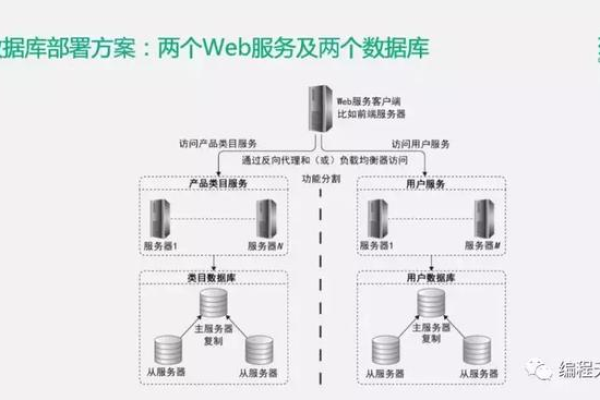
什么是分布式存储?它如何改变我们的数据处理方式?

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
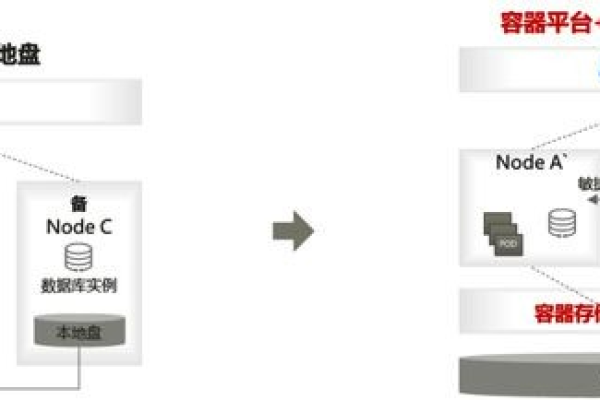
探索分布式存储,它如何改变我们的数据管理方式?
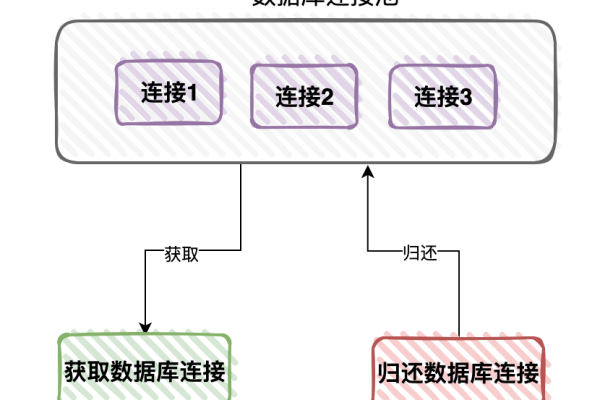
探索B域数据库,它是什么,以及它如何改变我们的数据处理方式?
Feed流深度学习是什么?它如何改变我们的数据处理方式?
大数据云存储如何改变我们的数据处理方式?
如何理解 Hologres 存储计算分离架构,既然支持内部表,为什么是存储计算分离?








