
上一篇
分布式存储和计算体系,如何实现数据的高效处理和存储?
分布式存储和计算体系是一种将数据和计算任务分散到多个节点上的技术架构。它通过并行处理提高性能,增加系统可靠性,并支持大规模数据处理。
分布式存储和计算体系

一、
分布式存储和计算体系是现代信息技术的重要组成部分,旨在通过分散处理和数据存储来提高系统的可扩展性、性能和容错能力,这种体系结构广泛应用于云计算、大数据处理、高性能计算等领域,为应对海量数据处理和复杂计算任务提供了有效的解决方案。
二、分布式存储体系
1. 定义与特点
分布式存储是一种数据存储方式,它将数据分散存储在多个独立的设备上,这些设备通过网络连接并协同工作,其特点包括:
高可用性:数据在多个节点上冗余存储,即使部分节点失效,数据仍然可用。
可扩展性:通过增加节点可以方便地扩展存储容量。
容错性:能够自动检测和修复错误,保证数据的一致性。
2. 常见架构
分布式存储系统的常见架构包括:
| 架构类型 | 特点 |
| 分布式文件系统 | 如HDFS(Hadoop Distributed File System),适用于大规模数据集的存储和访问。 |
| 分布式块存储 | 如Ceph,提供块级存储服务,适用于虚拟机和云环境中的数据存储。 |
| 分布式对象存储 | 如Amazon S3,提供对象级存储服务,适用于互联网应用和内容分发。 |
三、分布式计算体系
1. 定义与特点
分布式计算是一种计算模式,它将计算任务分解成多个子任务,分配给不同的计算节点并行执行,其特点包括:
并行性:多个计算节点同时处理不同子任务,提高计算效率。
可扩展性:可以通过增加计算节点来提升计算能力。
容错性:即使部分节点失效,其他节点仍然可以完成任务。
2. 常见框架
分布式计算的常见框架包括:
| 框架名称 | 特点 |
| Hadoop MapReduce | 适用于大规模数据集的批处理计算,通过Map和Reduce两个阶段处理数据。 |
| Apache Spark | 提供内存中计算,支持更快的数据处理速度,适用于实时数据处理。 |
| Dryad | 由微软开发的分布式计算框架,支持复杂的并行计算任务。 |
四、应用场景
1. 云计算
云计算利用分布式存储和计算体系提供弹性的计算资源和服务,用户可以根据需求动态调整资源使用量,常见的云计算平台包括Amazon Web Services(AWS)、Microsoft Azure和Google Cloud Platform(GCP)。
2. 大数据分析
大数据处理需要处理海量数据并进行复杂分析,分布式存储和计算体系能够高效地处理这些任务,Hadoop和Spark在大数据分析领域广泛应用。
3. 人工智能与机器学习
人工智能和机器学习需要大量的计算资源进行模型训练和推理,分布式计算框架如TensorFlow和PyTorch能够加速这些过程。
五、挑战与未来展望
1. 挑战
数据一致性和同步问题:在分布式环境中保持数据一致性是一个挑战。
网络延迟和带宽限制:网络性能可能影响分布式系统的效率。
安全性和隐私保护:如何在分布式环境中保护数据安全和隐私是一个重要问题。
2. 未来展望
边缘计算:将计算资源部署到靠近数据源的地方,减少网络延迟和带宽消耗。
量子计算:量子计算有望提供更高的计算能力,可能对分布式计算产生重大影响。
区块链技术:区块链可以提供去中心化的数据存储和交易机制,增强数据安全性和透明性。
六、FAQs
1. 什么是分布式存储?
答:分布式存储是一种将数据分散存储在多个独立设备上的数据存储方式,通过网络连接这些设备并协同工作,它的主要特点包括高可用性、可扩展性和容错性。
2. Hadoop和Spark有什么主要区别?
答:Hadoop主要采用MapReduce计算模型,适用于大规模数据集的批处理计算,而Spark提供内存中计算,支持更快的数据处理速度,适用于实时数据处理,Spark的RDD(Resilient Distributed Dataset)允许更高效的数据共享和重用。
小编有话说
分布式存储和计算体系作为现代信息技术的重要支柱,正不断推动着云计算、大数据、人工智能等前沿技术的发展,尽管面临诸多挑战,但其潜力和前景无疑是巨大的,我们期待未来有更多的创新和突破,为各行各业带来更多的可能性和机会。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/372782.html
相关文章
-
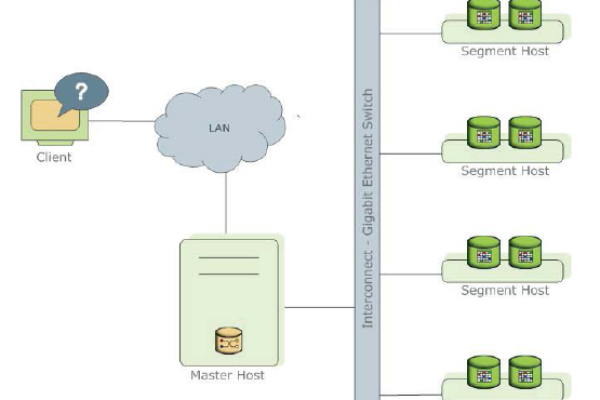
分布式存储和计算,如何优化数据管理和处理效率?
-
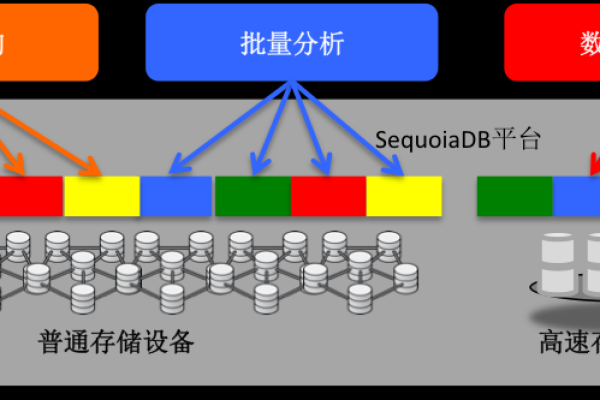
分布式块存储50t,如何实现高效的数据管理和存储?
-
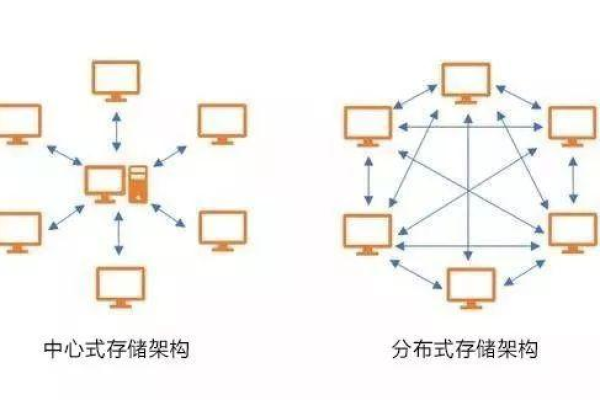
分布式存储中心如何实现数据的高效管理和安全性保障?
-
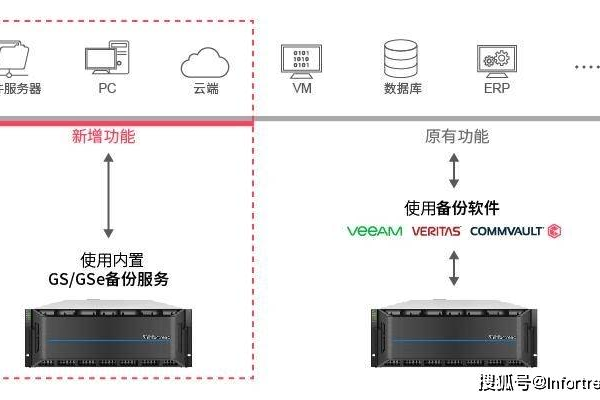
分布式存储一体机,如何实现数据的高效整合与管理?
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
如何优化分布式存储和计算系统以提升性能?
-
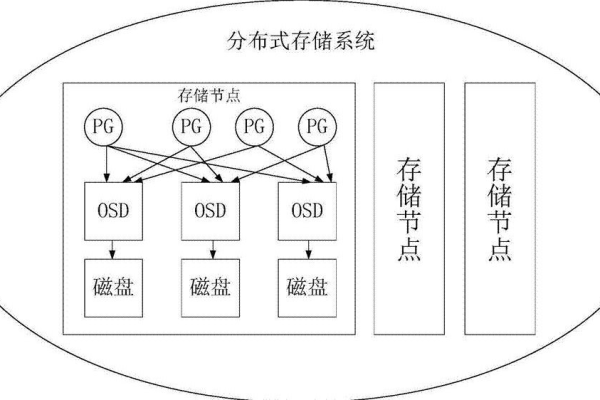
什么是分布式存储和计算系统?
-

5G时代,运营商需要何种分布式存储?(5g时代,运营商需要何种分布式存储技术)








