上一篇
如何优化分布式存储系统中的任务调度以提高性能和效率?
分布式存储任务调度是管理和分配计算资源以优化数据存取和处理的过程。
分布式存储任务调度

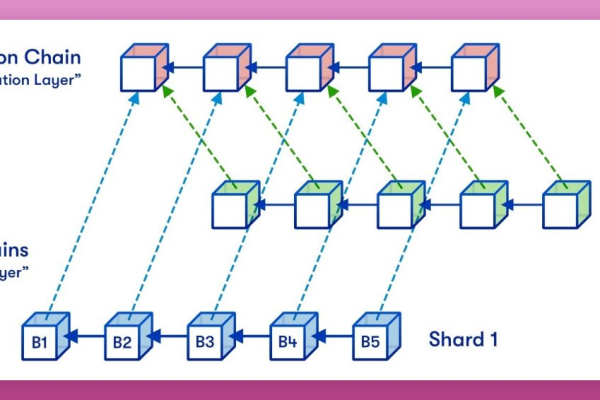
在现代计算环境中,数据量呈指数级增长,传统的集中式存储系统已无法满足大规模数据处理和存储的需求,分布式存储系统应运而生,它通过将数据分散存储在多个节点上,提高了系统的可靠性、可扩展性和性能,如何高效地管理和调度这些分布在不同节点上的存储任务,成为了一个关键问题,这就是分布式存储任务调度所要解决的问题。
核心概念
1、分布式存储:数据被分割成多个部分,并存储在通过网络连接的多台计算机(节点)上。
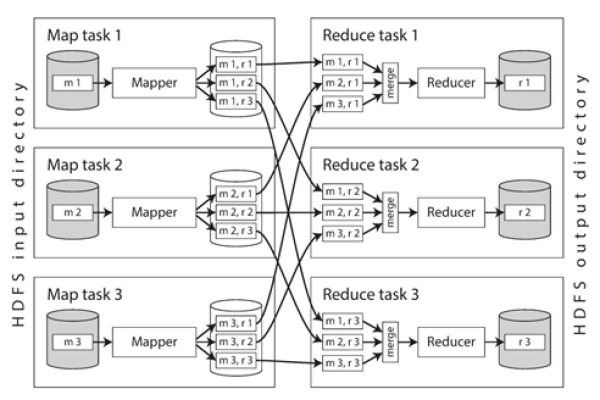
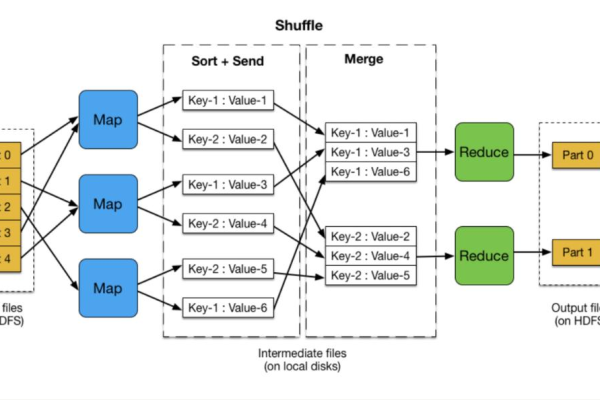
2、任务调度:根据预定的策略或算法,决定任务(如数据读写、备份等)在何时何地执行的过程。
3、负载均衡:确保所有节点的工作负载相对均匀,避免某些节点过载而其他节点空闲。
4、容错机制:即使部分节点发生故障,系统也能继续运行,保证数据的完整性和可用性。
分布式存储任务调度的挑战
数据一致性:在分布式环境中保持数据的一致性是一项挑战,尤其是在有节点故障的情况下。
网络延迟:节点间的通信可能受到网络延迟的影响,影响任务执行效率。
资源管理:合理分配和管理各节点的资源,以优化整体性能和成本。
安全性:保护数据免受未授权访问和攻击。
解决方案与技术
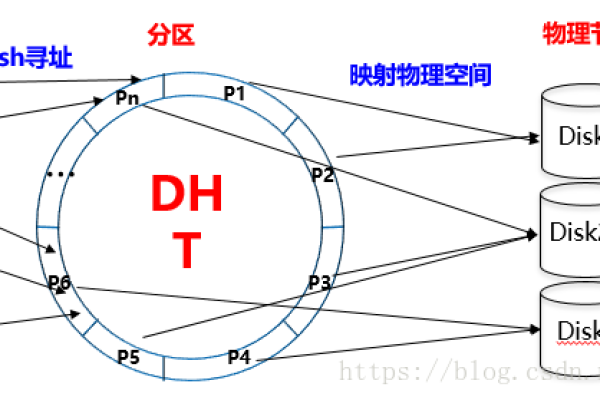
1、一致性哈希:一种分布式哈希算法,用于在节点间均匀分配数据,减少数据迁移和重新分配的开销。
2、副本机制:通过在不同节点上存储数据副本来提高可靠性和可用性。
3、动态负载均衡:根据实时监控的数据和系统状态,动态调整任务分配策略。
4、容错协议:如Raft、Paxos等,用于在分布式系统中达成共识,保证数据的一致性。
5、加密技术:使用强加密标准保护数据传输和存储过程中的安全。
表格示例:分布式存储系统特性比较
| 特性 | HDFS | Ceph | GlusterFS | Amazon S3 |
| 一致性模型 | 最终一致性 | 强一致性 | 最终一致性 | 近实时一致性 |
| 容错能力 | 高 | 非常高 | 高 | 高 |
| 扩展性 | 良好 | 优秀 | 良好 | 优秀 |
| 社区支持 | 活跃 | 非常活跃 | 活跃 | 有限 |
| 成本效益 | 中等 | 高 | 中等 | 变化大 |
FAQs
Q1: 分布式存储系统如何保证数据的高可用性?
A1: 分布式存储系统通常采用数据副本和冗余存储策略来保证数据的高可用性,Ceph使用CRUSH算法来分布和复制对象,即使部分硬件失败,也能保证数据的持续访问和完整性。
Q2: 在设计分布式存储任务调度系统时,应考虑哪些关键因素?
A2: 关键因素包括系统的可扩展性、容错能力、数据一致性、网络延迟、资源利用率以及安全性,还需要考虑成本效益比和易于维护性。
小编有话说
随着云计算和大数据技术的不断进步,分布式存储及其任务调度的重要性日益凸显,企业和组织需要根据自身的业务需求和技术能力,选择合适的分布式存储解决方案,并不断优化任务调度策略,以实现数据的高效管理和利用,随着人工智能和机器学习技术的发展,我们期待看到更加智能化的分布式存储任务调度系统,能够自动适应不同的工作负载和环境变化,提供更高效、更安全的数据服务。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/372342.html