上一篇
如何从MySQL题目中学习并掌握MySQL到MySQL的知识?
MySQL是一种流行的开源关系型数据库管理系统,它使用SQL(结构化查询语言)来访问和管理数据库。
MySQL到MySQL:数据同步的全面指南

一、背景介绍
在现代数据库管理中,数据同步是一个常见且重要的任务,无论是为了实现数据备份、高可用性还是负载均衡,将数据从一个MySQL数据库实时同步到另一个MySQL数据库都是至关重要的,本文将详细介绍如何使用不同的工具和方法来实现MySQL到MySQL的数据同步。
二、使用开源ETL工具DataX进行全量同步和批量更新
1. 准备工作
创建源表和目标表:
CREATE TABLE datax_src (
id BIGINT NOT NULL,
src_name VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE datax_target (
id BIGINT NOT NULL,
target_name VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;插入测试数据:
DELIMITER $$
CREATE DEFINER=root@% FUNCTIONAUTO_INSERT() RETURNS int(11)
BEGIN
DECLARE index_num INT DEFAULT 0;
WHILE index_num < 5000 DO
SET index_num = index_num + 1;
INSERT INTO datax_src VALUES (index_num, CONCAT('name', index_num));
END WHILE;
RETURN 0;
END$$
DELIMITER ;2. DataX配置文件示例
读取配置:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "1131310577",
"column": ["id", "src_name"],
"splitPk": "id",
"connection": [{
"table": ["datax_src"],
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3307/datax"]
}]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}]
}
}写入配置:
{
"job": {
"content": [{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 100,
"column": ["id", "src_name"],
"connection": [{
"table": ["datax_src"],
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3307/datax"]
}]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace-dirty",
"column": ["id", "target_name"],
"connection": [{
"table": ["datax_target"],
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3307/datax"]
}]
}
}
}],
"setting": {
"errorLimit": {"record": 0, "percentage": 0.02}
}
}
}运行DataX任务:
python datax.py /path/to/your/job_file.json
三、使用Flink CDC实现实时数据同步
1. 环境准备
安装MySQL和Flink:确保本地或服务器上已安装MySQL和Flink,并且Flink的版本支持CDC(如Flink 1.16.1)。
准备数据库:创建三个数据库flink_source、flink_sink和flink_sink_second,并在flink_source中创建表source_test,在flink_sink和flink_sink_second中创建表sink_test。
2. Flink SQL CLI作业开发
启动Flink SQL CLI:
./bin/sql-client.sh
创建Flink表并编写同步语句:
SET execution.checkpointing.interval = 3s;
CREATE TABLE source_test (
user_id STRING,
user_name STRING,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.3.31',
'port' = '3307',
'username' = 'root',
'password' = '******',
'database-name' = 'flink_source',
'table-name' = 'source_test'
);
CREATE TABLE sink_test (
user_id STRING,
user_name STRING,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.3.31:3307/flink_sink',
'table-name' = 'sink_test'
);
INSERT INTO sink_test
SELECT * FROM source_test;四、FAQs
Q1: DataX在同步过程中如何处理错误?如果同步任务失败,如何恢复?
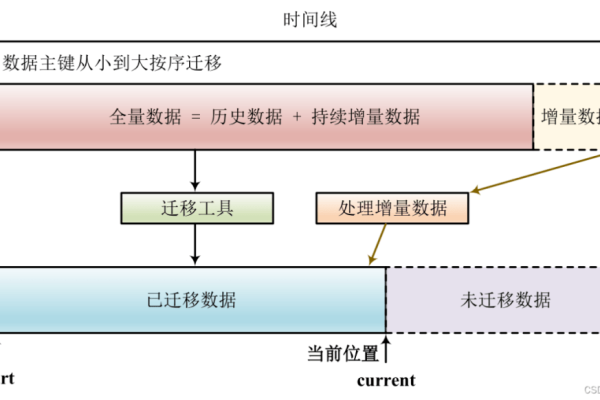
A1: DataX在配置中提供了errorLimit参数,可以设定记录错误阈值和错误百分比阈值,当同步任务出错时,可以根据需求选择继续重试或者中止任务,如果任务失败,可以通过查看日志文件定位错误原因,修改配置后重新运行任务,DataX还支持增量同步,可以从上次中断的地方继续执行。
Q2: Flink CDC在实时同步大量数据时,如何保证数据的准确性和一致性?
A2: Flink CDC利用MySQL的binlog进行数据捕获,可以实现精确的一次语义和正好一次语义,确保数据不丢失且不重复,通过设置检查点(Checkpoint)和保存点(Savepoint),Flink可以在任务失败时从上一个一致的状态恢复,保证数据的一致性,Flink还提供了多种容错机制,如重启策略和并行度调整,以适应不同的数据负载和系统资源。
小编有话说
无论是使用DataX进行全量同步和批量更新,还是利用Flink CDC实现实时数据同步,选择合适的工具和方法对于数据迁移和管理都至关重要,希望本文的介绍能够帮助大家更好地理解和应用这些技术,提升数据库管理的效率和可靠性,如果你有任何疑问或需要进一步的帮助,请随时联系我们。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/365522.html