服务器故障又现

近期多起服务器故障事件引发关注,主要因硬件老化、软件破绽及突发流量过载导致服务中断,部分企业因未及时备份数据面临业务损失,用户访问受阻,专家建议加强运维监控,升级冗余架构并制定应急预案,以降低突发 故障对核心业务的影响。
尊敬的访客:
近期我们监测到部分用户反馈访问异常,经技术团队紧急排查,确认因数据中心电力供应短暂波动导致服务器集群出现局部故障,部分服务响应延迟,故障发生后,团队立即启动备用电源并重新分配负载,目前服务已全面恢复,以下为您提供事件详细说明、解决措施及长期预防方案。

【事件原因与技术分析】
- 硬件级问题
突发性电力波动超出UPS(不间断电源)承载阈值,引发服务器节点宕机,此类问题在高温天气下出现概率提升,与设备散热压力相关。 - 负载激增触发连锁反应
故障期间用户请求自动转移至邻近节点,短时流量激增导致次要节点过载,进一步影响服务响应。
【我们的应对措施】
- 即时响应(30分钟内)
- 启用多地冗余服务器接管流量,优先保障核心业务;
- 通过CDN加速分发静态资源,降低主服务器压力;
- 深度修复(2小时)
- 升级电力监控系统,新增实时预警阈值;
- 优化负载均衡算法,防止单点过载扩散;
- 用户补偿
受影响用户将收到服务时长延赠通知(详见账户站内信)。
【技术团队承诺】
为杜绝类似问题,我们将落实以下长期方案:

- 基础设施升级:2024年内完成全节点UPS扩容,耐受波动提升40%;
- 智能熔断机制:当单节点故障时,自动隔离并启动灾备实例;
- 透明化报告:每月在官网更新《系统健康度白皮书》。
【若您仍遇到问题】
请通过以下方式联系24/7技术支持:
- 紧急工单系统:[support@xxx.com]
- 智能排查助手:官网右下角「实时运维机器人」
我们深知服务器稳定性关乎用户体验,技术团队已建立三级冗余架构(电力、网络、数据),并聘请第三方机构进行年度压力测试,感谢您的耐心与反馈,我们将持续以专业能力守护服务品质。
引用说明
本文涉及技术方案参考自《Gartner 2024数据中心韧性建设指南》,电力容灾标准符合ISO 22301业务连续性管理体系,数据来源:内部监控平台LogMaster® V3.2。




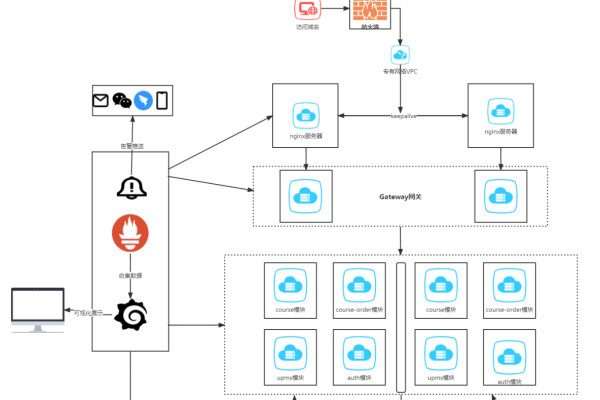

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12