
上一篇
怎么理解Hadoop中的HDFS
Hadoop是一个开源的大数据处理框架,它能够处理和存储大量的数据,在这个大数据处理的系统中,HDFS(Hadoop Distributed File System)扮演着非常重要的角色,什么是HDFS?又是如何工作的呢?
HDFS是Hadoop生态系统中的一部分,它是一个分布式文件系统,设计用于在大量的计算机集群上存储和管理大量数据,HDFS的主要目标是提供一个高度容错性的、高吞吐量的数据访问解决方案。
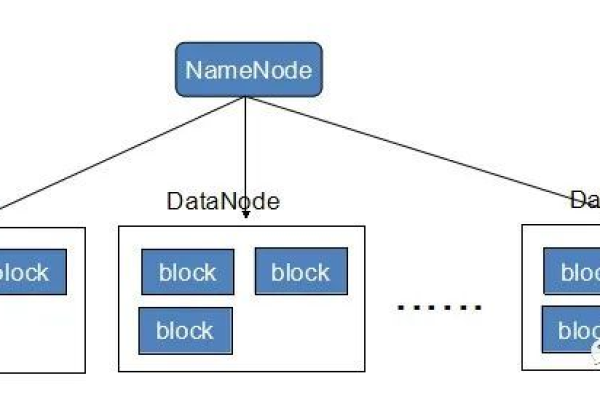
HDFS的核心设计理念是将数据分割成多个块,并将这些块分布在整个集群中的不同节点上,每个块都存储在一个独立的数据节点上,这种设计使得数据的读取和写入操作能够在多个节点之间并行进行,从而提高了数据处理的效率。
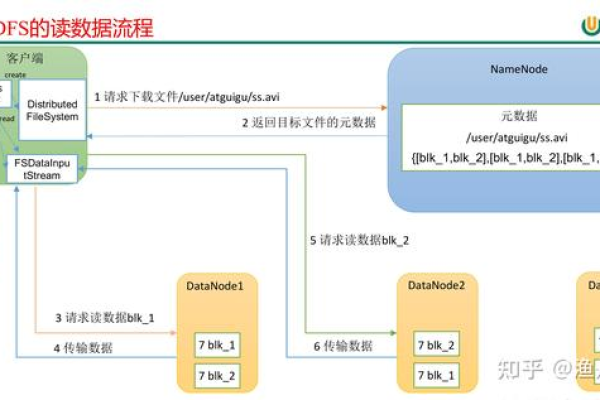
HDFS的工作方式是通过NameNode和DataNode来实现的,NameNode负责管理文件系统的命名空间,以及客户端对文件的读写操作,DataNode则是实际存储和管理数据的地方,它负责接收客户端的读写请求,并将数据块返回给客户端。
HDFS还提供了一种称为副本的机制,用于保证数据的可靠性,每个文件都会有多个副本存储在不同的节点上,这样即使某个节点发生故障,也不会影响到数据的完整性和可用性,HDFS还支持数据的压缩和备份,以进一步优化数据的存储和访问效率。
HDFS是一个高度可扩展、高容错性和高性能的分布式文件系统,它是Hadoop能够处理和存储大数据的关键组件,通过使用HDFS,我们可以有效地管理和处理海量的数据,从而在各种大数据应用中发挥重要的作用。
相关问题与解答:
1. HDFS是如何处理大数据的?
答:HDFS通过将大数据分割成多个块,并将这些块分布在整个集群中的不同节点上,从而实现了数据的并行处理,HDFS还提供了一种称为副本的机制,用于保证数据的可靠性。
2. HDFS是如何保证数据的一致性的?
答:HDFS通过NameNode和DataNode来管理文件系统的命名空间和数据块,所有的读写操作都需要经过这两个节点,当一个客户端对一个文件进行写操作时,这个操作会被路由到负责该文件的一个DataNode上,然后由这个DataNode将数据写入到本地的文件系统中,当这个DataNode发生故障时,其他的DataNode会将这个DataNode上的数据复制到自己的本地文件中,从而保证了数据的一致性。
3. HDFS的压缩机制是如何工作的?
答:HDFS支持数据的压缩和备份,以进一步优化数据的存储和访问效率,当一个客户端向HDFS写入一个文件时,可以选择是否启用压缩,如果启用了压缩,HDFS会在写入文件时先对数据进行压缩,然后再写入到磁盘中,当客户端读取这个文件时,HDFS会先将数据从磁盘中解压缩,然后再返回给客户端。
4. HDFS如何实现数据的备份?
答:HDFS通过将每个文件的多个副本存储在不同的节点上,实现了数据的备份,当一个DataNode发生故障时,其他的DataNode会将这个DataNode上的数据复制到自己的本地文件中,从而保证了数据的可靠性。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/345073.html
相关文章
-
爬虫数据存储hdfs_HDFS数据
-

Flink把hdfs集群里的core-启动集群说找不到hdfs,如何解决?
-
Flink独立集群与hdfs集群不在一起,flink如何配置checkpoint目录为hdfs?
-
客户端和服务器怎么理解_怎么理解SparkRTC的角色Role?
-
一个关于MySQL数据库中LIMIT和OFFSET用法的疑问句标题可以这样写,,MySQL查询优化,LIMIT 2、LIMIT 2,3与LIMIT 2 OFFSET 3有何区别?,清晰地表达了文章的核心主题,即探讨MySQL中LIMIT和OFFSET的不同用法及其对查询结果的影响。同时,它遵循了SEO原则,包含了关键词MySQL、LIMIT和OFFSET,有助于搜索引擎更好地理解和索引文章内容。此外,通过使用疑问句形式,标题还吸引了读者的注意力,激发了他们点击阅读的兴趣。
-
如何重置CAD设置?探索将CAD恢复为默认值的有效方法
-
MapReduce如何与HDFS及其他Hadoop组件协同工作?
-
NameNode 高可用性(HA)配置在HDFS中如何影响其他Hadoop组件的交互?