
 第1张")
上一篇
如何在服务器上安装和搭建Spark? (在服务器上装搭建spark)
安装和搭建Spark涉及下载Spark, 配置环境变量,设置Spark主节点和工作节点,以及启动集群。需确保Java和Scala兼容。
在服务器上安装和搭建Spark
Spark 是一种快速的、通用的集群计算框架,它非常适合于大规模数据处理,要在服务器上安装和搭建 Spark,我们需要进行以下几个步骤:
1、环境准备
在开始之前,确保你的服务器满足以下基本要求:
操作系统:推荐使用 Linux 或者 Unix 系统,如 Ubuntu、CentOS 等。
Java:Spark 需要 Java 运行时环境,建议安装 JDK 8。
内存与存储:根据数据处理需求,合理分配内存与存储资源。
2、下载 Spark
前往 Apache Spark 官网(https://spark.apache.org/downloads.html)选择合适的 Spark 版本进行下载,通常有两种下载选项:预编译版和源码版,预编译版是已经编译好的二进制包,可以直接使用;源码版需要自行编译。
3、解压 Spark
将下载的 Spark 压缩包上传至服务器,并解压到指定目录。
tar -xzvf spark-x.x.x-bin-hadoopx.x.tgz cd spark-x.x.x-bin-hadoopx.x
4、配置 Spark 环境变量
编辑 ~/.bashrc 或 ~/.bash_profile 文件,添加 Spark 的 bin 目录到 PATH 环境变量中。
export SPARK_HOME=/path/to/spark-x.x.x-bin-hadoopx.x export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
执行 source ~/.bashrc 或 source ~/.bash_profile 使配置生效。
5、配置 Spark 参数
进入 Spark 的配置目录 $SPARK_HOME/conf,复制一份 spark-env.sh.template 为 spark-env.sh,并编辑它来设置相关参数,
export JAVA_HOME=/path/to/java export SPARK_MASTER_HOST=your_server_ip export SPARK_WORKER_CORES=4 根据服务器核心数设置 export SPARK_WORKER_MEMORY=4g 根据服务器内存设置
6、启动 Spark
首先启动 master 节点:
start-master.sh
接着,在另一个终端中启动 worker 节点:
start-worker.sh spark://your_server_ip:7077
7、提交 Spark 作业
现在你可以使用 spark-submit 命令提交 Spark 作业了:
spark-submit --class org.apache.spark.examples.SparkPi --master spark://your_server_ip:7077 /path/to/spark-x.x.x-bin-hadoopx.x/examples/jars/spark-examples_2.x.x.jar 1000
以上就是在服务器上安装和搭建 Spark 的基本步骤,接下来我们可以通过一些常见问题与解答来进一步了解 Spark。
常见问题与解答
Q1: 我应该如何选择 Spark 的版本?
A1: 选择 Spark 的版本时,应考虑与 Hadoop 版本的兼容性以及社区支持情况,推荐使用最新稳定版。
Q2: Spark 作业运行缓慢,可能是哪些原因造成的?
A2: 可能的原因包括资源不足、数据倾斜、不合适的分区数量等,需要根据具体情况分析并进行调优。
Q3: 如何监控 Spark 作业的运行状态?
A3: 可以使用 Spark 的 Web UI(通常位于 http://your_server_ip:4040)来监控作业的运行状态,包括各个阶段的任务执行情况、内存使用情况等。
Q4: 如何在多台服务器上搭建 Spark 集群?
A4: 在每台服务器上重复上述安装和配置步骤,并在所有节点上启动 worker 节点指向同一个 master 节点即可,记得修改 SPARK_MASTER_HOST 为 master 节点的 IP 地址。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/335746.html
相关文章
-

服务器上装了Node,提高应用性能 (服务器上装了node)
-
如何在Linux上安装和配置Spark?
-
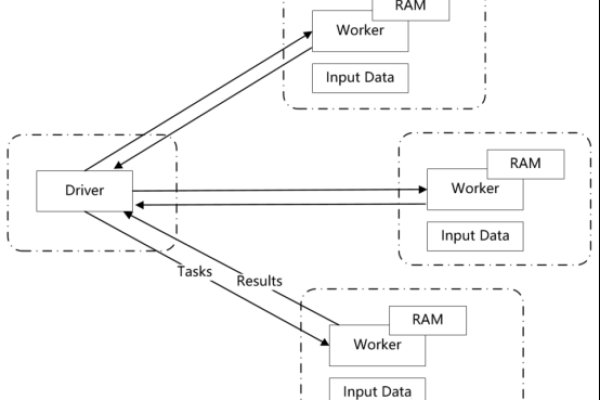
在分布式计算领域,MapReduce和Spark作为两种流行的大数据处理框架,它们在设计哲学、性能优化以及易用性方面存在显著差异。特别是当涉及到华为云的DLI(数据湖探索)服务中的Spark组件与华为云MRS(MapReduce服务)中的Spark组件时,用户可能会好奇这两者之间的具体区别是什么?
-

服务器高速运行不是梦,学会在服务器上安装ramdisk (在服务器上安装 ramdisk)
-
如何在Linux系统上安装Wireshark?
-
如何通过宝塔面板安装和搭建MongoDB?
-
如何通过宝塔面板安装和搭建MongoDB?
-
如何成功安装和搭建织梦DedeCMS的移动端站点?








