
上一篇
如何抓取html请求
抓取HTML请求通常指的是使用程序自动化地获取网页的HTML源码,这通常通过发送HTTP请求到服务器并接收响应来实现,在Python中,最常用的库来执行这些任务是requests和BeautifulSoup,以下是详细的技术教学步骤:

第一步:安装必要的库
在开始之前,你需要确保安装了requests和BeautifulSoup库,可以通过pip命令进行安装:
pip install requests beautifulsoup4
第二步:导入库
在你的Python脚本中,导入requests和BeautifulSoup库:
import requests from bs4 import BeautifulSoup
第三步:发送HTTP请求
使用requests库发送一个HTTP GET请求到你想要抓取的网页,如果你想获取Google首页的HTML内容,你可以这样做:
url = 'https://www.google.com' response = requests.get(url)
第四步:检查响应状态
在处理响应之前,最好先检查一下响应的状态码以确保请求成功:
if response.status_code == 200:
print("请求成功")
else:
print("请求失败,状态码:", response.status_code) 第五步:解析HTML内容
如果请求成功,你可以使用BeautifulSoup库来解析HTML内容,你需要创建一个BeautifulSoup对象,并指定解析器(’html.parser’):
soup = BeautifulSoup(response.text, 'html.parser')
第六步:提取数据
现在你可以使用BeautifulSoup提供的方法来提取你感兴趣的数据,如果你想提取所有的链接,你可以这样做:
for link in soup.find_all('a'):
print(link.get('href')) 第七步:保存或处理数据
根据你的需求,你可能想要保存提取的数据到文件,或者进一步处理它们,你可以将提取的链接保存到一个列表中:
links = [link.get('href') for link in soup.find_all('a')] 或者,你可以将整个HTML内容保存到一个文件中:
with open('output.html', 'w', encoding='utf8') as file:
file.write(str(soup)) 第八步:异常处理
在实际的网络请求中,可能会遇到各种异常,如网络问题、超时等,添加异常处理机制是很重要的:
try:
response = requests.get(url, timeout=10)
response.raise_for_status() # 如果状态不是200,引发HTTPError异常
except requests.RequestException as e:
print("请求出错:", e) 上文归纳
以上就是如何抓取HTML请求的基本步骤,通过requests库发送HTTP请求,使用BeautifulSoup解析和提取HTML内容,最后根据需求处理或保存数据,记得在实际操作中添加异常处理机制,以增强程序的健壮性。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/248453.html
相关文章

如何获取html请求

关于AngularJS中的ngbindhtml指令,一个原创的疑问句标题可以是,,如何在AngularJS中使用ngbindhtml指令安全地绑定并显示HTML内容?,清晰地表达了想要了解如何在AngularJS中利用ngbindhtml指令来绑定并显示HTML内容,同时强调了安全地这一关键点,表明提问者对于数据绑定的安全性有所关注。
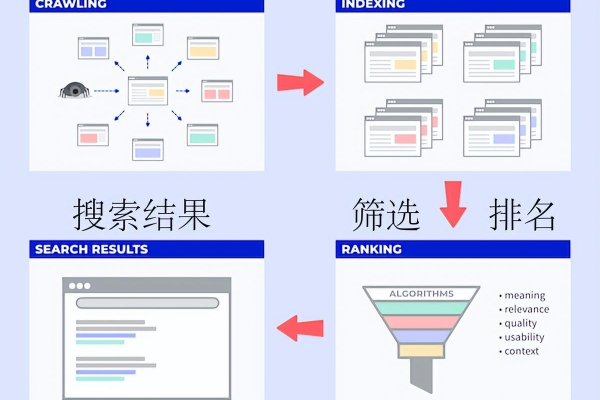
如何抓取百度搜索结果,百度搜索抓取策略类型包括「获取百度搜索结果」
限制引擎抓取怎么取消-引擎抓取要多久,禁止引擎抓取搜索页面

如何抓取网站html源码
如何在ASP中模拟CURL请求?探索实现方法与技巧

服务器双向ssl请求失败怎么解决
如何使用Fiddler为手机抓取HTTPS流量并安装抓包证书?








