从图中识别文字

方法、技术与应用场景全解析
在当今数字化时代,从图中识别文字的需求日益增长,无论是处理历史文档、扫描书籍内容,还是对图片中的文字信息进行提取分析,这项技术都有着广泛的应用,以下将详细介绍从图中识别文字的相关内容。
一、光学字符识别(OCR)技术基础
1、图像预处理
灰度化:彩色图像包含大量颜色信息,而灰度图像仅用亮度表示像素,减少了数据量且突出了文字与背景的对比度差异,一张彩色照片经过灰度化后,原本鲜艳的背景颜色变得单一,文字轮廓更加清晰可辨,为后续处理奠定基础。
降噪:图像在采集或传输过程中可能受到噪声干扰,如高斯噪声会使图像出现颗粒状斑点,通过滤波算法,如均值滤波、中值滤波等,可以有效去除噪声,平滑图像,避免噪声影响文字识别的准确性。
二值化:将图像像素值根据设定阈值转换为只有黑白两种颜色,合适的阈值选取至关重要,若阈值过高,文字部分可能被误判为背景;阈值过低,则背景会被当作文字,常见的 OCR 软件会提供自适应阈值算法,根据图像局部亮度和对比度动态确定阈值,确保文字与背景分离效果良好。
2、文字特征提取
笔画特征:文字由各种笔画组成,不同文字的笔画形态、粗细、长短、连接方式等存在差异,汉字“人”与“入”,笔画数量相同但笔画走向和结构不同,OCR 系统通过分析图像中文字的笔画特征,将其转化为计算机能够理解的特征向量,用于后续的识别匹配。
结构特征:除了笔画,文字的整体结构也是重要特征,对于印刷体文字,其排版规整,有固定的字体风格和字间距、行距等结构参数;手写体文字则更具个性化,每个人的书写习惯导致字形结构略有不同,OCR 技术需要针对不同类型文字的结构特点建立模型,以提高识别准确率。
二、常见 OCR 技术分类及原理
1、传统模式匹配法
模板匹配:预先存储标准文字模板,将待识别图像中的文字与模板逐一比对,这种方法简单直接,但局限性较大,对字体、字号、书写风格变化敏感,若模板中只有宋体字模板,遇到楷体字时就难以准确识别,而且当文字存在变形、倾斜等情况时,匹配效果会大打折扣。

特征匹配:提取文字的关键特征,如笔画数量、端点、交叉点等,构建特征库,识别时,将图像中文字的特征与特征库进行匹配,相比模板匹配,特征匹配对文字变化的适应性更强,但仍受特征提取准确性和特征库完备性的限制。
2、基于统计的学习方法
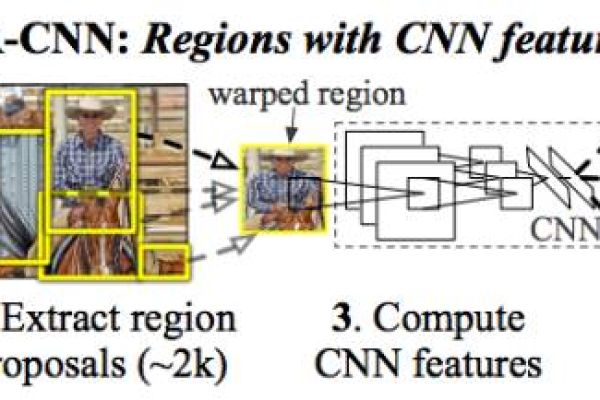
神经网络:利用多层神经网络模型,如卷积神经网络(CNN),CNN 自动学习图像中文字的层次化特征,从低层的笔画边缘等简单特征到高层的语义特征,通过大量标注样本训练,模型能够逐渐优化参数,提高识别精度,在识别车牌号码时,CNN 可以先学习数字和字母的边缘轮廓特征,进而识别出具体字符组合。
隐马尔可夫模型(HMM):常用于处理具有序列特性的数据,如文本,在文字识别中,将文字看作一系列状态的序列,每个状态对应一个笔画或字符单元,HMM 通过概率模型描述状态转移和观测概率,根据图像中文字的观测序列推断最可能的文字序列,对手写体文字识别效果较好,能有效处理连笔、笔画顺序变化等问题。
三、从图中识别文字的应用实例
1、文档数字化
图书馆古籍整理:许多图书馆收藏大量古籍善本,这些珍贵文献以纸质形式保存,通过 OCR 技术,可以将古籍中的文字转化为电子文本,方便学者研究查阅,同时减少对原书的翻阅磨损,实现文化遗产的数字化保护与传承。
企业档案管理:企业日常运营中产生大量纸质文件,如合同、报告等,利用 OCR 对这些文件进行文字提取并存储到电子数据库,便于快速检索、共享和数据分析,提高办公效率和管理规范化程度。
2、辅助视觉障碍人士

屏幕阅读软件:对于视力障碍者,屏幕阅读软件借助 OCR 技术实时识别屏幕上的文字信息,并以语音合成方式输出,使他们能够独立操作电脑、手机等设备,获取网页、文档等内容信息,提升生活质量和工作学习能力。
智能助视器:结合摄像头和 OCR 功能,助视器可以拍摄周围环境中的文字标识、菜单等,然后为视障者朗读内容,帮助他们更好地融入社会生活,如在餐厅点餐、商场购物等场景中发挥作用。
四、面临的挑战与发展趋势
1、挑战
复杂背景干扰:当文字处于复杂多变的背景中,如自然风景、纹理丰富的织物上时,准确分离文字与背景难度较大,容易导致识别错误。
多语言混合:在全球化环境下,同一图像中可能出现多种语言文字混合的情况,要求 OCR 系统具备多语言识别能力和准确的语言切换机制,目前一些小众语言的识别准确率仍有待提高。
艺术字体与手写体多样性:艺术字体设计独特、变形夸张,手写体因人而异且随意性大,这增加了特征提取和识别的难度,传统 OCR 技术往往难以应对,需要更先进的算法和大量的针对性训练数据。
2、发展趋势
深度学习持续优化:随着深度学习算法不断改进和计算资源提升,OCR 系统将能更精准地提取文字特征,尤其是对小样本、特殊字体和复杂场景下的文字识别能力会显著增强,通过迁移学习,利用大规模预训练模型在特定领域微调,快速适应新的文字识别任务。

与其他技术融合:结合计算机视觉中的图像分割、目标检测技术,先精确定位文字区域,再进行识别;融合自然语言处理技术,对识别后的文字进行语义理解、校正和上下文关联分析,提高识别结果的准确性和实用性。
从图中识别文字的技术在不断发展完善,其应用前景广阔,将为各领域的信息处理和智能化发展提供有力支持。
相关问答FAQs
问题1:OCR 技术对手写体文字识别准确率较低的原因是什么?
答:手写体文字识别准确率较低主要有以下原因,手写体具有高度的个性化和随意性,不同人的书写风格、笔画顺序、字间距等差异很大,不像印刷体那样规整统一,这使得难以建立通用的精准模型来适配所有手写体情况,手写体文字可能存在连笔、笔画省略、字迹模糊等问题,增加了准确提取笔画和结构特征的难度,手写体的书写速度、用力大小等因素也会影响文字的成像质量,进一步干扰识别过程。
问题2:如何提高 OCR 技术在复杂背景下的文字识别准确率?
答:可以采用以下方法提高 OCR 技术在复杂背景下的文字识别准确率,一是优化图像预处理步骤,如使用更先进的图像分割算法,像基于深度学习的 U-Net 网络,精确分离文字与背景,减少背景干扰,二是增加训练数据的多样性,特别是在复杂背景下采集包含各种字体、字号、颜色和光照条件的文字图像数据,让 OCR 模型学习在不同情境下的文字特征,三是采用多模态融合的方法,结合文字的颜色、纹理等信息与形状特征共同进行识别判断,提升模型对复杂背景的适应能力。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20