文件上传破绽,如何防范与应对?

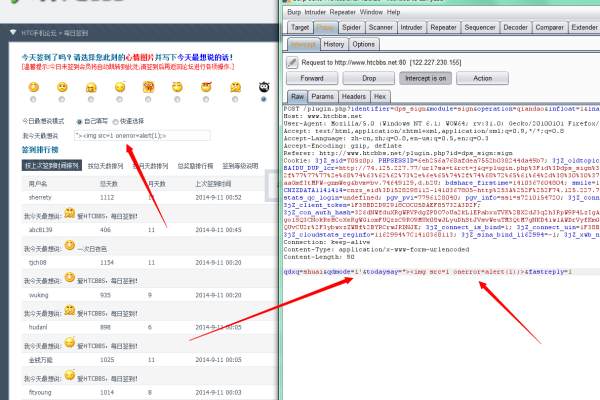
文件上传破绽是一种常见的网络安全问题,它发生在应用程序允许用户上传文件但未对上传的文件进行充分验证和过滤时,这种破绽可能被反面用户利用来上传反面文件,如干扰、载入或脚本,从而攻击服务器或访问其他用户的敏感信息。
文件上传破绽通常出现在Web应用程序中,尤其是那些允许用户自定义头像、分享文档或上传其他类型文件的应用,攻击者可以通过这些功能上传反面文件,如果服务器没有正确处理这些文件,攻击者就可能执行任意代码、窃取数据或破坏系统。
为了防范文件上传破绽,开发者应该采取以下措施:
1、限制上传文件的类型:只允许特定类型的文件上传,例如仅允许图片或PDF文件。
2、检查文件的MIME类型:确保上传的文件类型与声明的类型一致。
3、限制文件大小:设置合理的文件大小限制,防止用户上传过大的文件,这可能会消耗过多的服务器资源或用于拒绝服务攻击。
4、使用随机生成的文件名:避免使用用户提供的文件名,以防止路径遍历攻击。
5、存储文件在隔离区域:将上传的文件存储在一个独立的目录中,限制对这些文件的访问权限。
6、扫描上传的文件:使用反干扰软件或其他工具扫描上传的文件,以确保它们不包含反面代码。
7、实施安全策略:定期审查和更新安全策略,以应对新的威胁和技术。
以下是一个简单的表格,列出了文件上传破绽的一些常见原因和相应的预防措施:
| 原因 | 预防措施 |
| 未限制文件类型 | 只允许特定类型的文件上传 |
| 未检查MIME类型 | 验证上传文件的MIME类型 |
| 未限制文件大小 | 设置最大文件大小限制 |
| 使用用户提供的文件名 | 使用随机生成的文件名代替 |
| 文件存储位置不当 | 将上传的文件存储在隔离区域 |
| 缺乏安全扫描 | 对上传的文件进行干扰扫描和安全检查 |
| 安全策略过时 | 定期更新安全策略和防护措施 |
FAQs:
Q1: 如果我发现了一个网站存在文件上传破绽,我应该怎么办?
A1: 如果你发现了一个网站存在文件上传破绽,首先不要尝试利用这个破绽,你可以通过该网站的联系方式或者官方的安全团队报告这个问题,提供详细的信息,包括破绽的位置、如何发现以及可能的影响,这样可以帮助网站管理员更快地修复问题。
Q2: 作为开发者,我应该如何测试我的应用程序是否存在文件上传破绽?
A2: 作为开发者,你应该进行彻底的安全测试,包括渗透测试和代码审查,以确保你的应用程序没有文件上传破绽,你可以使用自动化工具来帮助检测潜在的安全问题,也可以雇佣专业的安全专家来进行深入的安全评估,确保你的应用程序遵循最佳安全实践,并且保持对最新安全威胁的关注。
小编有话说:
文件上传破绽是一个严重的问题,但它可以通过采取适当的预防措施来避免,作为用户,我们应该意识到这种风险,并且在遇到可疑的文件上传请求时要谨慎行事,作为开发者,我们有责任确保我们的应用程序是安全的,不会成为攻击者的突破口,通过教育和意识提升,我们可以共同减少这类安全事件的发生。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11