探究物理内存,它是什么,以及它在计算机中的作用如何?

物理内存,即计算机系统中直接与CPU进行数据交换的硬件存储单元,是计算机运行过程中不可或缺的重要组成部分,它主要用于存放当前正在运行的程序和数据,确保计算机能够快速、高效地执行任务,以下是关于物理内存的详细解释:
一、物理内存的定义与作用
物理内存,也称为实体内存或主存,是指计算机主板上的存储部件,用于临时存储当前正在运行的程序和数据,它是计算机系统中数据存取速度最快的存储部件,直接影响计算机的性能和稳定性,物理内存的大小通常以GB(吉字节)为单位来衡量,如8GB、16GB等。
二、物理内存的类型
物理内存主要由动态随机存取存储器(DRAM)芯片组成,这些芯片通过总线与CPU相连,实现数据的快速读写,根据技术规格的不同,物理内存可分为多种类型,如SDRAM、DDR SDRAM、DDR2 SDRAM、DDR3 SDRAM等,DDR(Double Data Rate)系列内存以其高数据传输速率和低功耗特性,在现代计算机系统中得到广泛应用。
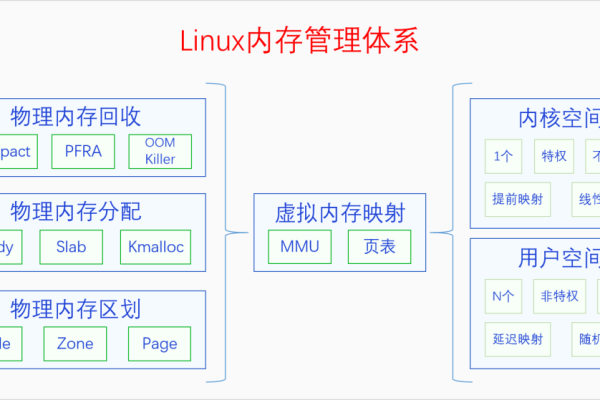
三、物理内存与虚拟内存的区别
虚拟内存是计算机系统内存管理的一种技术,它允许程序使用比实际物理内存更大的地址空间,当物理内存不足时,操作系统会将部分硬盘空间作为虚拟内存使用,以存储暂时不需要的数据,虚拟内存的访问速度远低于物理内存,因为它涉及到磁盘I/O操作,虽然虚拟内存可以缓解物理内存不足的问题,但过多的依赖虚拟内存会导致系统性能下降。
四、物理内存的重要性
物理内存的大小对计算机性能有着至关重要的影响,足够的物理内存可以确保操作系统和应用程序流畅运行,减少因内存不足而导致的卡顿、延迟等问题,物理内存还对系统的稳定性和安全性起着重要作用,当物理内存耗尽时,系统可能会出现崩溃、数据丢失等严重后果。
五、物理内存的选择与升级
在选择物理内存时,需要考虑计算机的主板规格、CPU支持的最大内存容量以及个人需求等因素,对于日常办公和娱乐用途,8GB至16GB的物理内存已经足够,而对于专业图形设计、视频编辑等高性能需求的应用,则可能需要更大容量的物理内存。
升级物理内存通常涉及购买合适规格的内存条并安装到计算机主板上的空闲内存插槽中,在升级前,建议备份重要数据并咨询专业人士以避免不必要的损失。
六、常见问题解答(FAQs)
Q1: 如何查看计算机的物理内存大小?
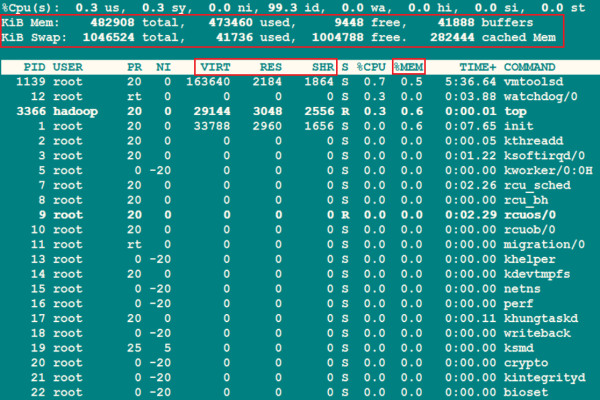
A1: 可以通过多种方法查看计算机的物理内存大小,在Windows系统中,可以按下Ctrl + Shift + Esc键打开任务管理器,点击“性能”选项卡即可查看物理内存的使用情况和总大小,在macOS系统中,可以点击屏幕左上角的苹果图标选择“关于本机”,然后在弹出的窗口中查看内存信息。
Q2: 物理内存越大越好吗?
A2: 虽然物理内存越大通常意味着更好的性能和多任务处理能力,但并不是越大越好,过多的物理内存可能会导致资源浪费和成本增加,在选择物理内存大小时,需要根据个人需求和预算进行权衡,对于一般用户来说,8GB至16GB的物理内存已经足够满足日常使用需求。
以上就是关于“物理内存”的问题,朋友们可以点击主页了解更多内容,希望可以够帮助大家!






热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22