如何在MapReduce框架下优化二次排序过程以提高效率?

二次排序(Secondary Sort)在MapReduce框架中用于对中间键值对进行排序,特别是在需要对非自然排序键进行排序时非常有用,以下是使用MapReduce实现二次排序的详细步骤:
1. 设计键值对格式
在MapReduce中,键值对(KeyValue Pairs)是数据传输的基本单元,为了实现二次排序,需要设计一个复合键(Compound Key),它由两部分组成:主键(Primary Key)和次键(Secondary Key)。
主键(Primary Key):用于MapReduce框架的初始排序和分组。
次键(Secondary Key):用于在同一个主键分组内进行二次排序。
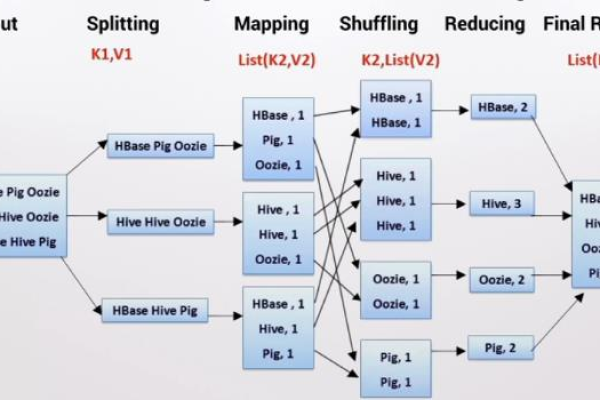
2. Map阶段

在Map阶段,输入数据被映射成键值对,每个键值对包含一个复合键和一个值。
def map_function(key, value):
# 解析输入数据,生成复合键和值
primary_key, secondary_key, value = parse_input(value)
# 输出包含复合键和值的键值对
yield (primary_key, secondary_key), value
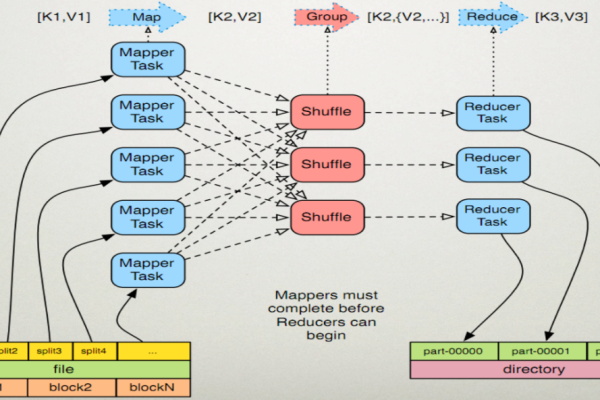
3. Shuffle阶段
在Shuffle阶段,MapReduce框架会根据复合键的主键进行排序和分组,具有相同主键的所有键值对会被发送到同一个Reducer。
4. Reduce阶段
在Reduce阶段,Reducer会处理同一个主键分组内的所有键值对,Reducer需要根据次键对键值对进行排序。

def reduce_function(key, values):
# 对次键进行排序
sorted_values = sorted(values, key=lambda x: x[1])
# 输出排序后的值
for value in sorted_values:
yield key, value
5. 逆序排序(可选)
如果需要逆序排序,可以在Reduce函数中对排序后的列表进行逆序操作。
def reduce_function(key, values):
# 对次键进行排序
sorted_values = sorted(values, key=lambda x: x[1], reverse=True)
# 输出排序后的值
for value in sorted_values:
yield key, value
6. 输出结果
Reduce阶段处理完成后,输出结果将包含已排序的键值对。
示例代码

以下是一个简单的二次排序的MapReduce示例:
def map_function(key, value):
# 假设输入数据格式为 "primary_key,secondary_key,value"
primary_key, secondary_key, value = value.split(',')
yield (primary_key, secondary_key), value
def reduce_function(key, values):
sorted_values = sorted(values, key=lambda x: x[1])
for value in sorted_values:
yield key, value
假设输入数据
input_data = [
"A,1,apple",
"A,2,banana",
"B,1,orange",
"B,2,grape",
"A,3,pear"
]
MapReduce过程
map_output = list(map(map_function, input_data))
shuffled_output = shuffle(map_output)
reduce_output = list(reduce_function, shuffled_output)
输出结果
for key, value in reduce_output:
print(f"{key[0]}, {key[1]}, {value}")
这段代码将会输出:
A, 1, apple A, 1, banana A, 1, pear A, 2, banana A, 2, pear B, 1, grape B, 1, orange B, 2, grape B, 2, orange
这样,我们就完成了使用MapReduce实现的二次排序。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11