什么是CDN加速?限时瞬秒活动又是怎么回事?

CDN加速限时瞬秒
在当今数字化时代,内容分发网络(CDN)已成为提升网站性能和用户体验的关键工具,特别是在某些特定时段,如限时瞬秒活动期间,CDN的作用尤为显著,本文将详细探讨CDN加速在限时瞬秒中的应用及其优势,同时提供一些实际操作建议。
一、什么是CDN加速?
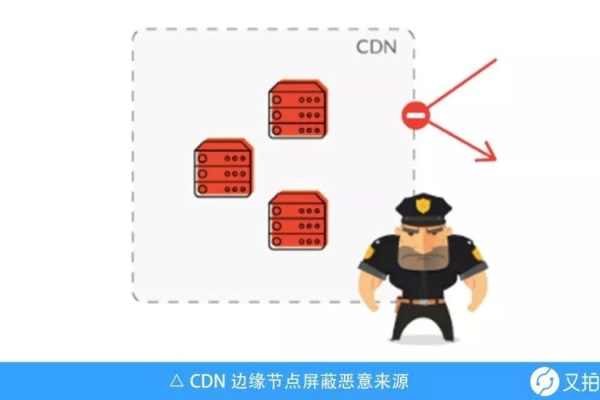
CDN是一种分布式服务器系统,通过在全球各地部署节点,将源站的内容缓存到离用户最近的节点上,当用户请求访问网站时,系统会自动调度到最近的节点响应,从而大大减少了传输延迟,提高了访问速度。
二、CDN加速在限时瞬秒中的重要性
限时瞬秒活动通常伴随着短时间内的高并发访问量,这对网站的服务器性能和稳定性提出了极高的要求,CDN加速在这一过程中起到了至关重要的作用:
1、提高页面加载速度:CDN可以将网站的静态资源(如图片、CSS、JavaScript等)缓存到全球各地的节点上,用户访问时直接从最近的节点获取资源,极大地缩短了加载时间。
2、减轻服务器负载:通过将部分请求分流到CDN节点,源站服务器的压力得以减轻,从而提高了整体系统的稳定性和抗压能力。
3、优化用户体验:快速的页面加载速度和稳定的访问体验有助于提升用户的满意度和转化率,特别是在限时瞬秒这种竞争激烈的场景下。
三、如何有效利用CDN加速进行限时瞬秒
为了充分发挥CDN加速的优势,以下是一些具体的操作建议:
1、选择合适的CDN服务商:确保所选的CDN服务商拥有广泛的节点分布和强大的技术支持,能够满足高并发访问的需求。
2、合理配置缓存策略:根据网站的实际情况,制定合理的缓存策略,确保静态资源能够及时更新并缓存到CDN节点上。
3、实时监控与调整:在限时瞬秒活动期间,实时监控CDN的性能指标,如响应时间、命中率等,并根据需要进行调整优化。
4、结合其他优化措施:除了CDN加速外,还可以考虑使用Gzip压缩、合并小文件、懒加载等技术手段进一步提升页面加载速度。
四、常见问题解答
Q1: CDN加速是否适用于所有类型的网站?
A1: 虽然CDN加速对大多数网站都有显著的提升效果,但并非所有类型的网站都适合使用CDN,对于高度动态化、实时交互性强的网站,可能需要更复杂的加速方案。
Q2: 使用CDN加速是否会增加额外的成本?
A2: 使用CDN加速确实会产生一定的费用,但这些费用通常与所带来的性能提升和用户体验改善相比是值得的,许多CDN服务商提供灵活的计费方式,可以根据实际需求进行选择。
CDN加速在限时瞬秒活动中具有不可替代的作用,通过合理配置和使用CDN加速,可以显著提升网站的访问速度和稳定性,从而为用户提供更好的购物体验。
到此,以上就是小编对于“CDN加速限时瞬秒”的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位朋友在评论区讨论,给我留言。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/99685.html