csv格式导入数据库

在当今数据驱动的时代,CSV(逗号分隔值)格式因其简单性和广泛兼容性而成为数据交换的常用格式,将CSV格式的数据导入数据库是许多项目和业务流程中的常见需求,以下将详细介绍如何将CSV格式的数据导入到不同类型的数据库中,包括关系型数据库(如MySQL、PostgreSQL)和非关系型数据库(如MongoDB)。
一、准备工作
1、确认CSV文件格式:确保CSV文件的编码格式(如UTF-8)、列分隔符(通常为逗号)、文本限定符(通常为双引号)等符合预期,并且第一行包含列名。
2、选择目标数据库:根据项目需求选择合适的数据库系统。
3、安装必要的工具或库:对于编程方式导入,可能需要安装如Python的pandas、sqlalchemy等库。
二、导入步骤
关系型数据库(以MySQL为例)
创建数据库和表:在MySQL中创建一个新的数据库和对应的表结构,假设CSV文件中包含员工信息,表结构可能如下:
| 字段名 | 数据类型 |
| id | INT |
| name | VARCHAR(255) |
| age | INT |
| department | VARCHAR(255) |
编写导入脚本:使用编程语言(如Python)结合数据库连接库(如pymysql)编写脚本,示例代码如下:
import pandas as pd
from sqlalchemy import create_engine
读取CSV文件
df = pd.read_csv('employees.csv')
创建数据库连接
engine = create_engine('mysql+pymysql://username:password@localhost/database_name')
将数据写入数据库
df.to_sql('employees', con=engine, if_exists='replace', index=False)
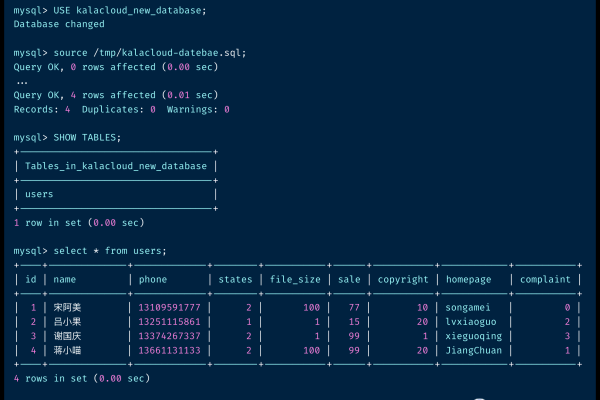
执行脚本并验证:运行脚本后,通过SQL查询验证数据是否成功导入。
2. 非关系型数据库(以MongoDB为例)
安装MongoDB客户端库:确保已安装MongoDB并启动服务,同时安装相应的Python客户端库(如pymongo)。
编写导入脚本:使用Python和pymongo库编写脚本,示例代码如下:
import pandas as pd
from pymongo import MongoClient
读取CSV文件
df = pd.read_csv('employees.csv')
连接到MongoDB
client = MongoClient('localhost', 27017)
db = client['mydatabase']
collection = db['employees']
将数据写入MongoDB
records = df.to_dict(orient='records')
collection.insert_many(records)
执行脚本并验证:运行脚本后,通过MongoDB shell或GUI工具验证数据是否成功导入。
三、注意事项
数据清洗:在导入前对CSV数据进行清洗,处理缺失值、异常值等。
性能考虑:对于大量数据,考虑分批导入或使用更高效的导入工具/方法。
安全性:保护数据库访问凭证,避免在脚本中硬编码敏感信息。
四、相关问答FAQs
Q1:如果CSV文件中的列名与数据库表中的列名不匹配怎么办?
A1:可以在导入前使用pandas的rename方法或SQL语句中的AS关键字来映射列名,在pandas中可以这样做:df.rename(columns={'old_column_name': 'new_column_name'}, inplace=True)。
Q2:如何处理CSV文件中的重复数据?
A2:在导入前,可以使用pandas的drop_duplicates方法去除重复数据。df.drop_duplicates(inplace=True),也可以在数据库层面设置唯一约束来防止重复数据的插入。
小编有话说:将CSV格式的数据导入数据库虽然看似简单,但实际操作中可能会遇到各种问题,如数据格式不一致、性能瓶颈等,在进行导入操作前,务必做好充分的准备工作和测试,以确保数据的准确导入和系统的稳定运行,希望本文能为你提供有益的参考和帮助!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/96177.html