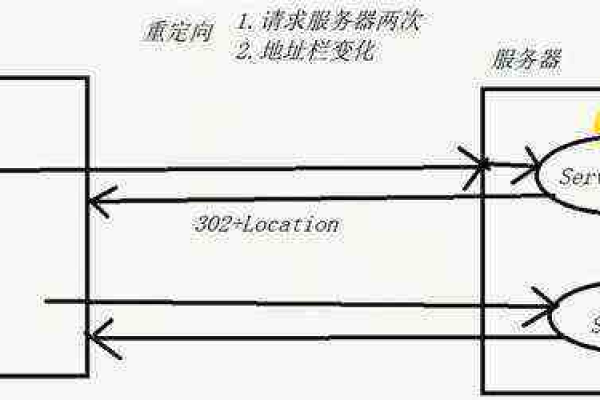
如何正确配置虚拟主机的域名重定向?

虚拟主机域名重定向设置
概述
在构建和维护网站时,虚拟主机和域名重定向是两个关键概念,虚拟主机允许在一个物理服务器上运行多个域名,每个域名可以有不同的网站内容;而域名重定向则是将一个域名或URL路径重定向到另一个域名或路径的过程。
虚拟主机配置
1、Apache虚拟主机配置:
打开Apache的配置文件(通常是httpd.conf或apache2.conf)。
找到<VirtualHost>标签并进行相应设置,如:
<VirtualHost *:80>
ServerName example.com
DocumentRoot /var/www/example.com
</VirtualHost>
ServerName指定了虚拟主机的域名,DocumentRoot指定了网站内容的根目录。
2、Windows虚拟主机301重定向:
在网站根目录下新建一个文件夹(如301)。
进入虚拟主机网站的“主机管理子目录绑定”,绑定新目录到目标域名。
在301目录下创建index.asp或php文件,添加301重定向代码,如:
Response.AddHeader "Location" ,";
%>
保存并上传到301目录,访问原域名应自动跳转到新域名。
3、云虚拟主机301重定向:
登录云虚拟主机管理页面,选择基础环境设置 > 301重定向。
选择源域名和目标域名,点击添加并确认。
如需HTTPS重定向,确保源域名和目标域名都开启了HTTPS功能。
4、直接编辑.htaccess文件:
备份当前目录下的.htaccess文件。
打开.htaccess文件,加入以下规则:
RewriteEngine On
RewriteCond %{HTTP_HOST} !^www.domain.com$ [NC]
RewriteRule ^(.*)$ http://www.domain.com/$1 [L,R=301]
上述规则将非www的域名重定向到www域名。
5、使用cPanel设置301重定向:
登录cPanel,选择Domain > Redirects。
选择相应的选项完成设置。
6、DNSPOD设置301重定向:
将NS服务器地址设置为DNSPOD。
在DNSPOD上设置显性URL转发到www域名。
注意事项
在进行域名跳转配置时,需考虑搜索引擎优化(SEO)的影响,建议使用301永久重定向而非302临时重定向。
保持网站结构的一致性和内容的连贯性,以避免对用户和搜索引擎造成不良影响。
对于不支持301重定向的虚拟主机类型,可能需要寻找其他解决方案或联系服务提供商咨询。
通过以上步骤,您可以有效地在虚拟主机上设置域名重定向,实现灵活的网站管理和良好的用户体验。
各位小伙伴们,我刚刚为大家分享了有关“虚拟主机域名重定向怎么设置”的知识,希望对你们有所帮助。如果您还有其他相关问题需要解决,欢迎随时提出哦!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/89855.html