轻松上手:如何添加主机到Godaddy (godaddy添加主机)

在Godaddy中添加主机需登录账户,选择域名管理,进入域名设置,配置DNS记录,添加A记录或CNAME,指向新主机IP。
在网络世界中,拥有一个域名是建立在线身份的第一步,而在众多域名注册商中,GoDaddy 无疑是最受欢迎和知名的之一,当你在 GoDaddy 注册了域名之后,接下来的一个重要步骤就是将这个域名指向你的网站托管服务,即添加主机记录,以下是详细的步骤指南,帮助你轻松上手,完成在 GoDaddy 添加主机的操作。
1、登录 GoDaddy 账户
你需要登录到你的 GoDaddy 账户,在浏览器中输入 GoDaddy 的网址并访问,使用你的用户名和密码登录。
2、选择你的域名
成功登录后,进入你的产品列表页面,找到你想要管理的域名,点击它旁边的“管理”按钮。
3、访问域名管理界面
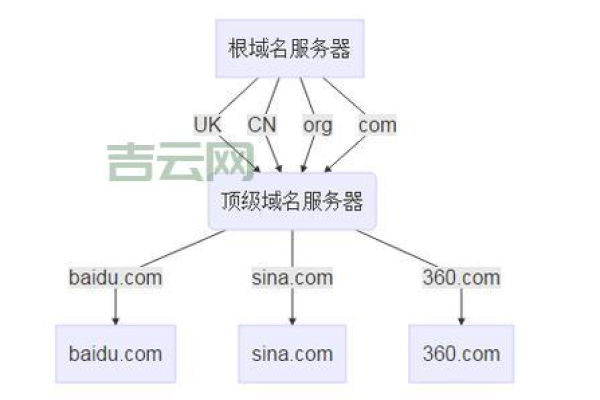
在域名管理界面中,你会看到多个选项,包括域名信息、名称服务器、DNS 管理等,我们需要的是 DNS 管理,也就是管理你域名下的 DNS 记录的地方。
4、进入 DNS 管理
点击“DNS 管理”或类似的链接,进入 DNS 管理区域,这里列出了你的所有 DNS 记录,包括 A 记录、CNAME 记录、MX 记录等。
5、添加新的 A 记录
")
为了将域名指向你的主机服务器,你需要添加一个新的 A 记录,A 记录用于指定域名对应的 IP 地址,点击“添加”按钮开始创建新的 A 记录。
6、填写 A 记录详情
在新建 A 记录的表格中,你需要填写以下信息:
主机:这里通常留空或填写 @,代表根域名,如果你想要添加子域名的 A 记录,“www”,则在这里填写。
指向(指向类型):选择 “指向一个 IPv4 地址”。
点此更改(IPv4 地址):输入你的网站托管服务器提供的 IP 地址。
TTL:保留默认设置或根据托管服务商的建议填写。
7、保存记录
")
填写完毕后,点击“保存”按钮,新的 A 记录就会被添加到你的 DNS 配置中。
8、等待 DNS 生效
DNS 记录的更新可能需要一些时间来传播到整个互联网,这个过程叫做 DNS 传播,通常这个过程会在几分钟到几小时内完成,但有时也可能长达 48 小时,你可以使用多种在线工具检查 DNS 记录是否已经生效。
9、测试域名解析
一旦 DNS 记录生效,你就可以通过在浏览器中输入你的域名来测试网站是否可以正常访问,如果一切设置正确,你应该能够看到你的网站内容。
以上就是在 GoDaddy 添加主机的详细步骤,记得在进行任何 DNS 修改之前,最好先做好笔记和备份,以防出现意外情况需要恢复,而且,确保你从托管服务商那里获取的 IP 地址是正确的。
相关问题与解答
Q1: 如果我在 GoDaddy 上添加了 A 记录,但是网站无法正常访问,可能是什么原因?
")
A1: 如果你的网站无法通过新添加的 A 记录访问,可能是 DNS 尚未完全传播,或者你输入的 IP 地址不正确,请确认 IP 地址无误,并耐心等待至少 48 小时以完成 DNS 传播。
Q2: 我可以在 GoDaddy 上为同一个域名添加多个 A 记录吗?
A2: 可以的,实际上,对于同一个域名,你可以添加多条 A 记录,指向不同的 IP 地址,这在某些特定的负载均衡和故障转移场景中非常有用。
Q3: 我是否需要为 www 子域名和根域名分别添加 A 记录?
A3: 是的,通常建议为 www 子域名和根域名都添加 A 记录,即使它们指向相同的 IP 地址,这样无论是通过 www 还是直接通过根域名访问,用户都可以到达你的网站。
Q4: 如果我的托管服务提供了 CNAME 而不是 IP 地址,我该如何设置?
A4: 如果托管服务提供了 CNAME,那么你应该在 GoDaddy 添加 CNAME 记录而不是 A 记录,CNAME 记录允许你将域名指向另一个域名,而不需要知道实际的 IP 地址,只需在“指向”部分选择“指向一个域名”并填写托管服务提供的域名即可。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11