如何查看服务器的地址?

ipconfig并回车;在linux或mac系统中,打开终端,输入
ifconfig或
ip addr并回车。这将显示网络接口的ip地址信息。
要查看服务器的地址,可以通过多种方法实现,以下是一些常见的方法和步骤:
1、通过命令行工具
Windows系统:在命令提示符(CMD)中输入ipconfig /all,可以列出服务器内的所有网络接口信息,包括IPv4地址、子网掩码、网关和MAC地址。
Linux/Mac系统:打开终端,输入ifconfig或ip addr show,可以显示类似的网络接口信息。
2、使用图形界面
Windows系统:打开控制面板,点击“网络和Internet”,再点击“查看网络状态和任务”,选择正在使用的网络连接,右键点击并选择“状态”,然后点击“详细信息”查看IP地址。
Linux/Mac系统:通常可以在系统设置中找到网络选项,点击当前连接的网络,可以看到详细的网络信息。
3、通过路由器管理界面
如果服务器通过路由器连接到局域网,并且DHCP功能已启用,可以登录路由器管理界面来查看已分配给服务器的IP地址。
4、使用在线工具
访问在线网站如WhatIsMyIP或IPinfo,输入目标域名即可获取其IP地址,这些工具不仅提供IP地址,还可能显示额外的信息如地理位置、ISP等。
5、通过API查询
使用在线API服务如IPinfo API或Whois API,可以发送HTTP GET请求来查询IP地址,这种方法适合开发人员在应用程序中集成IP查询功能。
6、使用浏览器开发者工具
打开Chrome或Firefox浏览器的开发者工具,切换到“Network”标签,刷新页面后可以看到所有网络请求的详细信息,包括目标服务器的IP地址。
7、查看网络配置文件
根据服务器所运行的操作系统,查找相应的网络配置文件,Ubuntu和Debian系统的网络配置文件通常位于/etc/network/interfaces或/etc/network/interfaces.d/目录中;CentOS和Fedora系统的网络配置文件通常位于/etc/sysconfig/network-scripts/ifcfg目录中。
查看服务器地址的方法多种多样,可以根据具体需求和环境选择合适的方法,无论是通过命令行工具、图形界面、路由器管理界面、在线工具、API查询还是浏览器开发者工具,都能有效地获取服务器的IP地址。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/85627.html
相关文章
-

如何查看服务器的地址和端口?
-
如何查看服务器登录设备的地址查询?
-
如何查看服务器的访问IP地址?
-
如何查看服务器的外网地址?
-
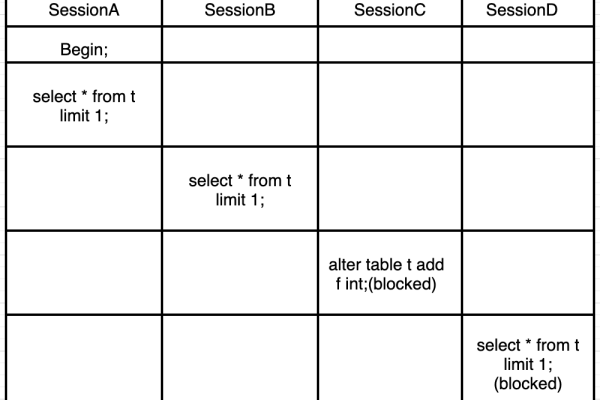
以下几个疑问句标题可供选择,,如何查看 RDS for MySQL 数据库死锁日志及 MySQL 表格字段相关问题解析,RDS for MySQL 死锁日志怎么查看?与 MySQL 表格字段操作探讨,怎样查看 RDS for MySQL 数据库的死锁日志?关于 MySQL 表格字段的思考,RDS for MySQL 数据库死锁日志查看方法与 MySQL 表格字段研究,如何查看 RDS for MySQL 数据库死锁日志?对 MySQL 表格字段的分析
-
如何正确修改缓存服务器的地址以及内网地址?
-
如何查找兄弟打印机代理服务器的地址?
-

如何查找我的我的世界局域网服务器的地址?
