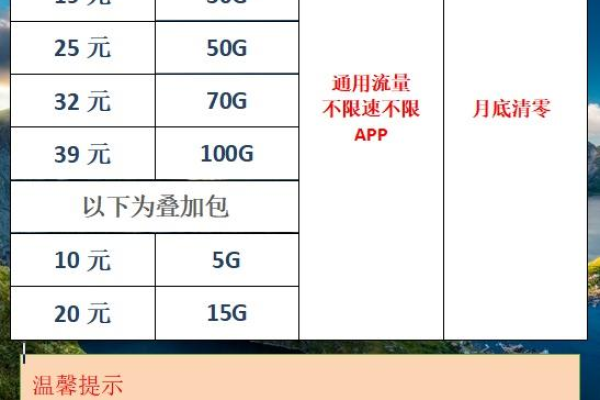
服务器每月流量消耗情况如何?

服务器的流量消耗取决于多种因素,包括网站或应用的类型、访问量、内容类型(如文本、图片、视频)、用户行为以及是否有下载或流媒体服务等,为了给出一个大致的估计,我们可以分析几个常见的场景:
小型个人网站或博客
月均流量: 10GB 50GB
特点: 主要是文本和少量图片,偶尔有视频嵌入,访问量相对较低。
中型商业网站
月均流量: 100GB 1TB
特点: 包含大量图片、多媒体内容,可能有在线交易或用户生成的内容,访问量中等至较高。
大型电商平台或新闻门户
月均流量: 1TB 10TB
特点: 高分辨率图片、视频内容丰富,实时数据更新,极高的访问量和并发用户。
视频流媒体或游戏服务器
月均流量: 10TB 100TB+
特点: 高清甚至4K视频流,大量数据传输,极高的带宽需求,持续的高并发连接。
表格示例:不同类型网站的预估月流量
| 网站类型 | 预估月流量范围 | 主要影响因素 |
| 小型个人网站/博客 | 10GB 50GB | 文本、少量图片,低访问量 |
| 中型商业网站 | 100GB 1TB | 图片、多媒体内容,中等至高访问量 |
| 大型电商平台/新闻门户 | 1TB 10TB | 高分辨率图片、视频,实时数据更新,极高访问量 |
| 视频流媒体/游戏服务器 | 10TB 100TB+ | 高清/4K视频流,大量数据传输,持续高并发连接 |
影响服务器流量的因素
1、内容类型: 文本内容相比图片、视频占用更少的流量,高清视频尤其是直播视频,会极大增加流量消耗。
2、用户数量与行为: 访问者越多,产生的流量自然越大,用户在网站上的活动(如观看视频、下载文件)也会影响流量。
3、页面加载速度与优化: 优化图片大小、使用CDN加速、开启压缩等技术可以有效减少单个用户的数据传输量。
4、第三方嵌入内容: 如社交媒体分享按钮、广告、外部视频等,这些内容由第三方服务器提供,但会在你的网站上显示,从而计入你的流量统计。
5、安全措施与备份: 定期备份数据和实施安全措施(如DDoS防护)可能会产生额外流量,但这是必要的维护成本。
FAQs
Q1: 我的网站流量突然大幅增加,可能是什么原因?
A1: 流量激增可能由多种因素引起,包括但不限于:
网站内容被广泛分享或出现在热门平台上。
进行了成功的营销活动或SEO优化,吸引了更多访客。
遭遇了DDoS攻击或其他反面流量。
发布了新功能或产品,引起了用户的高度兴趣。
建议检查服务器日志、分析工具报告,并考虑联系您的托管服务提供商以获取更多见解和支持。
Q2: 如何有效管理和控制服务器流量?
A2: 管理和控制服务器流量的策略包括:
内容分发网络(CDN): 使用CDN可以将内容缓存到全球各地的节点上,减少主服务器的直接流量负担。
流量监控与分析: 定期监控流量模式,识别高峰时段和异常流量,以便做出相应调整。
优化资源: 压缩图片、合并CSS/JS文件、启用浏览器缓存等,减少页面大小和加载时间。
限制带宽: 对于共享主机或有限带宽计划,可以设置带宽上限来避免超额费用。
扩展基础设施: 根据需要升级服务器配置或采用云服务自动扩展功能,以应对流量增长。
安全防护: 实施防火墙规则、WAF(Web应用防火墙)和DDoS防护措施,保护网站免受反面攻击导致的流量泛滥。
各位小伙伴们,我刚刚为大家分享了有关“服务器每个月多少流量”的知识,希望对你们有所帮助。如果您还有其他相关问题需要解决,欢迎随时提出哦!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/85385.html