cdn爬虫

CDN与爬虫的详细解析
CDN
CDN,全称为Content Delivery Network,即内容分发网络,它是通过在全球各地部署服务器,利用分布式系统来提高网站访问速度和性能的技术,CDN的基本原理是将源站的内容缓存到不同区域的目标节点上,当用户请求内容时,CDN会根据用户的地理位置或网络条件,将请求定向到离用户最近或负载最轻的节点,从而减少延迟,提高响应速度。
CDN的组成部分包括源站、边缘服务器、负载均衡器、缓存机制和DNS解析等,源站是存储原始内容的主要服务器;边缘服务器则分布在全球各地,负责缓存内容并响应用户请求;负载均衡器用于在多个服务器之间分配请求,确保高可用性和负载均衡;缓存机制则存储了源站内容的副本,以便快速响应后续请求;DNS解析负责将用户请求导向最近的CDN节点。
CDN的工作原理可以概括为:用户发起请求后,DNS解析将域名指向最近的CDN节点;用户向该节点发送请求,如果缓存中存在请求内容,则直接返回给用户,否则向源站获取内容,并在缓存中保存以备后续请求使用。
爬虫
爬虫,也被称为网络爬虫或网络蜘蛛,是一种自动化程序,用于在互联网上浏览和提取信息,爬虫通过模拟人类用户访问网页的行为,从网页中提取数据并将其存储或进行进一步处理,爬虫可以自动遍历互联网上的各个网页,并根据预设的规则和算法来解析和收集感兴趣的信息。
爬虫可以分为良性爬虫和恶性爬虫两类,良性爬虫通常用于搜索引擎索引、数据分析等合法目的,它们遵循robots.txt协议并尊重网站的使用条款;而恶性爬虫则无视这些规则,可能会进行数据盗窃、内容剽窃等反面活动。
爬虫的工作流程一般包括确定起始网页、发送HTTP请求获取网页内容、解析HTML提取所需数据、处理数据以及跟踪链接递归抓取等步骤,在编写爬虫时,需要考虑网页的反爬虫机制、遵守robots.txt文件以及限速策略等因素。
CDN与爬虫的关系
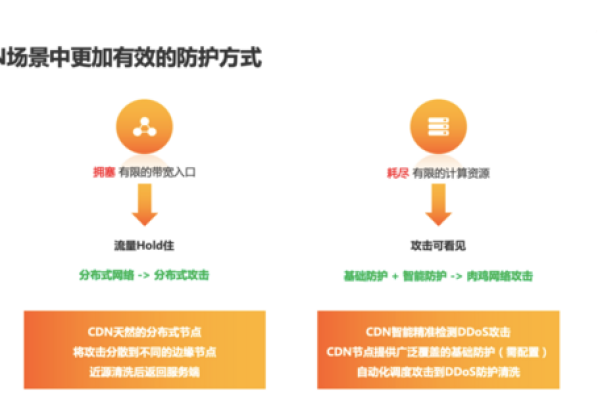
CDN与爬虫之间存在着密切的关系,CDN通过缓存和加速技术提高了网站的访问速度和性能,从而为用户提供了更好的体验;CDN也提供了一些安全功能来抵御爬虫的反面抓取行为。
CDN可以通过IP黑名单和白名单控制访问权限,限制某些地区的IP地址访问或只允许可信赖的IP地址访问,从而防止反面爬虫的抓取行为,CDN还可以利用用户代理和行为分析识别异常流量模式,实时调整策略以应对潜在的威胁。
需要注意的是,虽然CDN可以在一定程度上抵御爬虫的抓取行为,但并不能完全阻止所有爬虫的访问,在使用CDN时仍需结合其他安全措施来保护网站内容的安全和完整性。
FAQ
问题1:CDN能否完全防止爬虫的抓取?
答:不能,CDN可以在一定程度上抵御爬虫的抓取行为,但并不能完全阻止所有爬虫的访问,需要结合其他安全措施来共同保护网站内容的安全和完整性。
问题2:如何区分良性爬虫和恶性爬虫?
答:良性爬虫通常用于搜索引擎索引、数据分析等合法目的,它们遵循robots.txt协议并尊重网站的使用条款;而恶性爬虫则无视这些规则,可能会进行数据盗窃、内容剽窃等反面活动,通过分析用户行为模式和访问频率等特征可以区分两者。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/83447.html