上一篇
如何利用MapReduce技术高效计算事件数量?
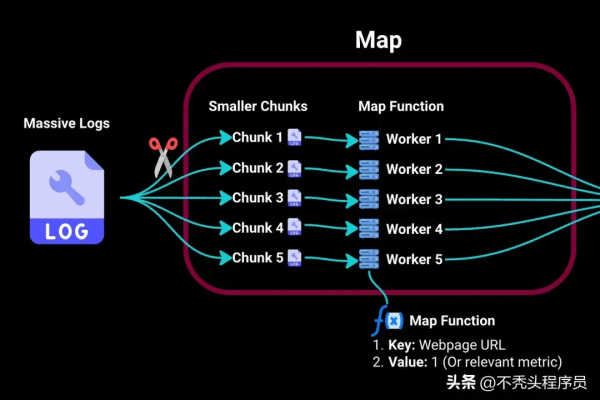
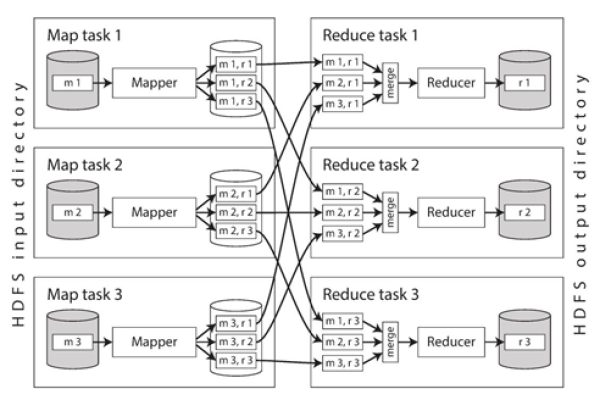
MapReduce是一种编程模型,用于处理和生成大数据集。 eventcount_MapReduce可能是一个使用MapReduce技术来计算事件数量的程序或函数。具体实现取决于输入数据和需求。
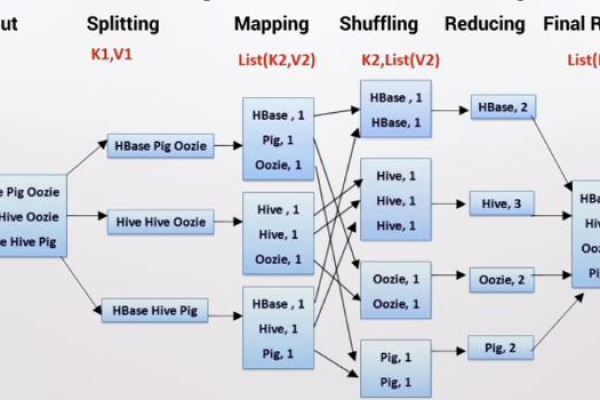
MapReduce是一种编程模型,用于处理和生成大数据集,通常在分布式计算环境中实现,它最早由Google提出,并广泛应用于大数据处理框架如Hadoop中,MapReduce的核心思想是将任务分解为两个主要阶段:映射(Map)和归约(Reduce),Map阶段将输入数据拆分成多个片段,并对每个片段进行处理,生成中间键值对;Reduce阶段则将这些中间结果合并,以生成最终输出。
MapReduce计数器
MapReduce中的计数器用于收集作业的统计信息,包括数据处理量、执行时间等,计数器分为内置计数器和用户自定义计数器,内置计数器由Hadoop自动维护,用于记录作业运行过程中的各项指标,而用户自定义计数器则可以根据特定需求进行定制。
MapReduce内置计数器
Hadoop为每个作业维护若干内置计数器,这些计数器被分成多个组,每组包含不同的计数器,以下是一些主要的内置计数器及其说明:
MapReduce任务计数器
| 计数器名称 | 说明 |
| MAP_INPUT_RECORDS | 所有map任务已处理的输入记录数 |
| MAP_OUTPUT_RECORDS | 所有map任务产生的输出记录数 |
| MAP_OUTPUT_BYTES | 所有map任务产生的未经压缩的输出数据字节数 |
| REDUCE_INPUT_GROUPS | 所有reducer已处理的分组个数 |
| REDUCE_INPUT_RECORDS | 所有reducer已处理的输入记录数 |
| REDUCE_OUTPUT_RECORDS | 所有reducer产生的输出记录数 |
文件系统计数器
| 计数器名称 | 说明 |
| BYTES_READ | 从文件系统中读取的字节数 |
| BYTES_WRITTEN | 向文件系统中写入的字节数 |
| READ_OPS | 文件系统中进行的读操作数量 |
| WRITE_OPS | 文件系统中进行的写操作数量 |
作业计数器
| 计数器名称 | 说明 |
| Launched map tasks | 启动的map任务数 |
| Launched reduce tasks | 启动的reduce任务数 |
| Total time spent by all maps in occupied slots (ms) | 所有map任务在占用的插槽中花费的总时间 |
| Total time spent by all reduces in occupied slots (ms) | 所有reduce任务在占用的插槽中花费的总时间 |
用户自定义计数器
虽然Hadoop内置的计数器已经相当全面,但在一些特定业务场景下,用户可能需要自定义计数器来满足特定的统计需求,用户可以通过context.getCounter方法获取一个全局计数器,并在程序中适当位置对其进行更新,假设我们需要统计一批日志中某个单词的出现次数,可以在Mapper类中定义一个计数器,每当解析到该单词时,计数器加一:
public class LogMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text k = new Text();
private final LongWritable out = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
boolean result = parseLog(line, context);
if (!result) {
return;
}
k.set(line);
context.write(k, out);
}
private boolean parseLog(String line, Context context) {
String[] words = line.split("\s+");
for (String word : words) {
if ("apple".equals(word)) {
context.getCounter("logMapper", "parseLog_true").increment(1);
return true;
}
}
context.getCounter("logMapper", "parseLog_false").increment(1);
return false;
}
}在这个例子中,我们定义了两个自定义计数器:“parseLog_true”和“parseLog_false”,分别用于统计日志中出现和未出现单词“apple”的次数。
FAQs
什么是MapReduce的内置计数器?
MapReduce的内置计数器是Hadoop为每个作业自动维护的一系列统计信息工具,用于记录作业执行过程中的各种指标,如输入输出数据量、任务执行时间等,这些计数器被分为多个组,每组包含不同的计数器,帮助用户监控作业执行情况并进行故障诊断。
如何在MapReduce中创建和使用自定义计数器?
在MapReduce中创建和使用自定义计数器需要以下几个步骤:
1、获取计数器:通过context.getCounter方法获取一个全局计数器,并指定其所属的组名和计数器名称。
2、更新计数器:在程序的适当位置调用计数器的increment方法,根据需要增加或减少计数器的值。
3、使用计数器:在Mapper或Reducer类中使用自定义计数器,根据业务逻辑进行统计,统计日志中某个单词的出现次数。
通过以上步骤,用户可以灵活地在MapReduce作业中使用自定义计数器来满足特定的统计需求。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/80604.html