设置切换cdn

设置切换 CDN 的详细指南
一、什么是 CDN?
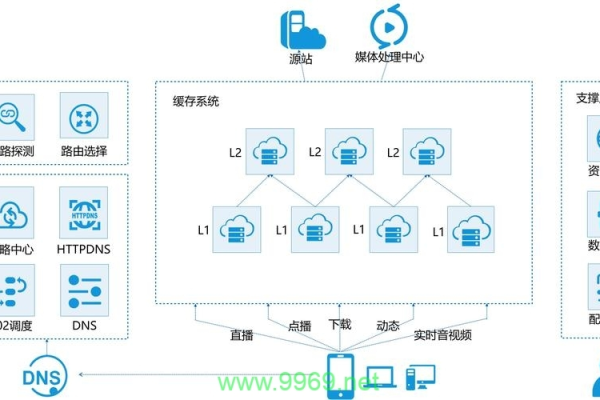
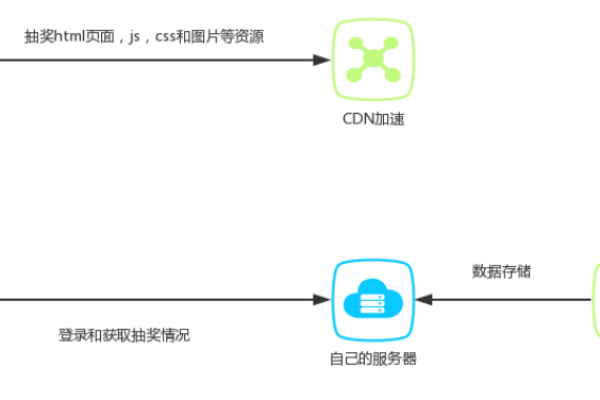
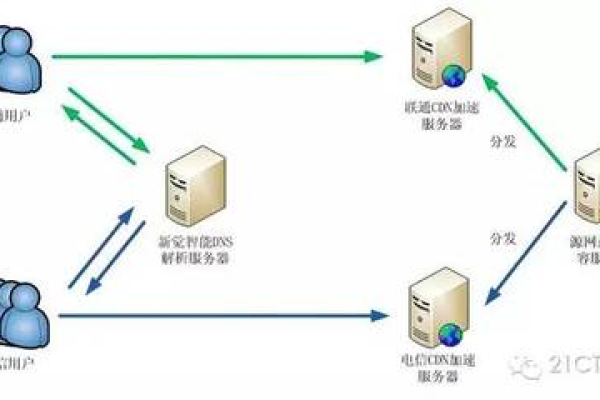
CDN(Content Delivery Network),即内容分发网络,是一种通过在多个地理位置分布服务器来加速网站内容交付的技术,当用户请求网站内容时,CDN 会从距离用户最近的服务器提供内容,从而减少延迟并提高加载速度。
二、为什么需要切换 CDN?
1、性能优化:不同地区的 CDN 服务质量可能有所不同,切换到更优质的 CDN 可以提升网站性能。
2、成本控制:某些 CDN 提供商可能收费较高,切换到性价比更高的 CDN 可以降低成本。
3、功能需求:不同的 CDN 提供商可能提供不同的功能,如缓存策略、安全防护等,根据网站的需求选择合适的 CDN 可以满足特定的功能需求。
三、切换 CDN 的步骤

(一)选择新的 CDN 提供商
| 因素 | 考虑要点 |
| 性能 | 查看 CDN 提供商的服务器分布、网络带宽、缓存命中率等指标,确保其能够提供良好的性能。 |
| 价格 | 比较不同 CDN 提供商的价格方案,包括流量费用、存储费用、请求费用等,选择符合预算的提供商。 |
| 功能 | 了解 CDN 提供商提供的功能,如缓存策略、安全防护、压缩优化等,确保能够满足网站的需求。 |
| 技术支持 | 查看 CDN 提供商的技术支持水平,包括响应时间、解决问题的能力等,以便在遇到问题时能够及时得到帮助。 |
(二)备份原 CDN 配置
在进行切换之前,务必备份原 CDN 的配置信息,包括域名解析记录、缓存规则、安全防护设置等,这样可以在切换过程中出现问题时快速恢复原配置。
(三)在新 CDN 上配置域名
1、登录新 CDN 提供商的控制台,添加要切换的域名。
2、根据提示进行域名解析设置,将域名的 DNS 记录指向新 CDN 的服务器。
3、等待 DNS 解析生效,这通常需要一定的时间,具体取决于 DNS 服务器的更新频率。
1、如果原 CDN 上有缓存的内容,需要将这些内容迁移到新 CDN 上,可以通过下载原 CDN 上的缓存文件,然后上传到新 CDN 的相应目录中。
2、确保新 CDN 上的缓存文件与原 CDN 上的文件一致,以避免出现缓存不一致的问题。

(五)测试新 CDN
1、在切换完成后,使用工具测试网站在不同地区的加载速度和性能,确保新 CDN 能够正常工作。
2、检查网站的页面显示是否正常,链接是否有效,图片、视频等资源是否能够正常加载。
3、如果发现问题,及时排查原因并进行修复。
四、相关问题与解答
(一)切换 CDN 会影响网站的 SEO 吗?
答:切换 CDN 本身不会直接影响网站的 SEO,但如果在切换过程中出现了网站访问异常、页面加载缓慢等问题,可能会对 SEO 产生一定的影响,在切换 CDN 时,要确保切换过程平稳,尽量减少对网站访问的影响。

(二)如何判断新 CDN 的性能是否优于原 CDN?
答:可以通过以下几种方法来判断新 CDN 的性能是否优于原 CDN:
1、加载速度测试:使用工具如 GTmetrix、PageSpeed Insights 等测试网站在不同地区的加载速度,比较新 CDN 和原 CDN 的加载时间。
2、性能指标对比:查看新 CDN 和原 CDN 的性能指标,如缓存命中率、带宽利用率等,判断新 CDN 的性能是否更优。
3、用户体验评估:收集用户反馈,了解用户在使用新 CDN 后的体验是否有所改善,如页面加载更快、视频播放更流畅等。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20