上一篇
如何在MySQL中实现端到端的机器学习场景?
本文主要介绍了MySQL在机器学习中的应用,包括数据预处理、特征选择、模型训练等端到端场景。通过实例演示了如何使用MySQL进行 机器学习任务,为数据库管理员和数据科学家提供了一种新的机器学习解决方案。
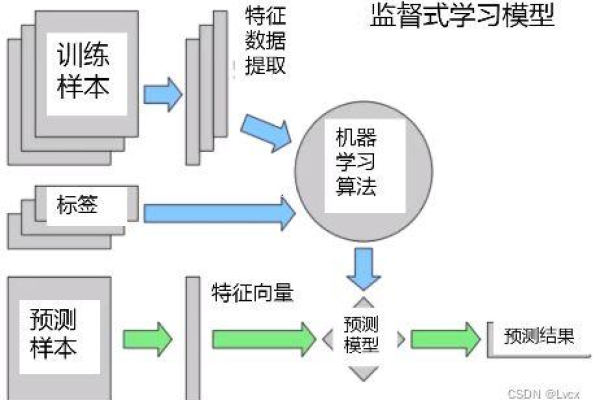
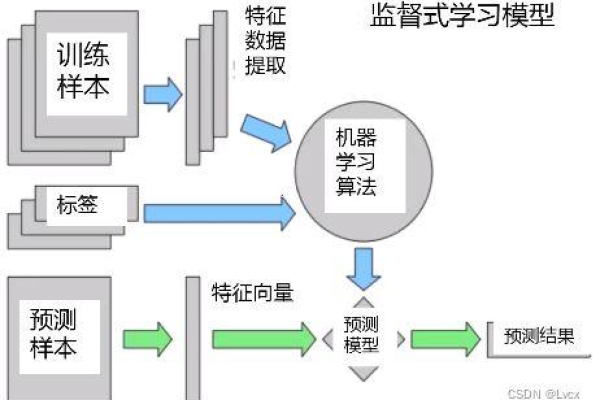
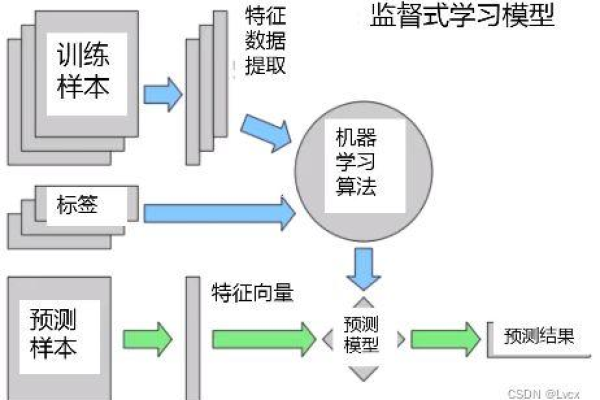
在当今时代,机器学习正变得越来越普及,而MySQL结合机器学习的端到端场景则代表了一项前沿技术的应用,在这一过程中,从数据的准备到模型的训练,再到最终的部署与应用,每一个环节都是相互关联、不可或缺的,下面将详细探讨这一过程的每个关键步骤:

1、数据准备
数据接入:首先需要将MySQL数据库中的数据接入到机器学习平台中,这涉及到数据的抽取、转换和加载(ETL)过程,确保数据的可用性和一致性。
数据清洗:数据清洗是确保数据质量的关键步骤,它包括识别并处理缺失值、异常值和重复数据等。
数据标注:对于监督学习来说,数据标注是必要的一步,它涉及为数据打上标签,以便训练出的模型能够正确学习和分类数据。
2、模型训练
特征工程:在数据准备工作完成后,需要进行特征工程以选择和构造对模型训练有帮助的特征,良好的特征可以极大提升模型的性能。
模型选择:根据具体的问题类型和数据特性选择合适的机器学习模型,对于分类问题可以选择决策树、随机森林或神经网络等。
训练与验证:使用准备好的数据对模型进行训练,并通过交叉验证等方法评估模型的性能,反复调整模型参数直至达到满意的效果。
3、模型部署
模型优化:在模型正式部署前,需要对其进行优化,保证模型的响应时间和准确率满足实际应用需求。
部署方式:机器学习模型可以部署为API服务,也可以集成到现有的应用程序中,选择合适的部署方式对于模型的应用至关重要。
监控与维护:部署后的模型需要持续监控其性能,并根据反馈进行必要的维护和更新,确保模型长期有效。
4、应用与反馈
实际应用:将训练得到的模型应用于实际问题的解决中,如通过机器学习模型预测用户行为、推荐系统等。
收集反馈:在模型应用过程中收集用户的反馈,以及模型的实际效果数据,这对于后续的模型迭代非常有帮助。
持续迭代:根据实际应用中收集到的数据和反馈,不断迭代优化模型,以适应不断变化的数据和业务需求。
MySQL结合机器学习的端到端场景展现了如何从传统的数据库技术迈向智能化的数据处理,这不仅提高了数据处理的效率和智能程度,也为企业带来了更多的价值,随着技术的不断发展和应用的深入,未来这一领域还会有更多的创新和突破,值得持续关注和研究。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/76269.html