如何系统地学习并掌握MySQL数据库的基础知识和高级技能?

课程基本信息
1、中文名称:MySQL 数据库基础
2、课程类别:必修
3、适用专业:商务数据分析
4、理论学时:24学时
5、实验学时:24学时
6、总学分:3.0学分
7、先修课程:《计算机导论》、《程序设计基础》
8、开课教研室:软件工程教研室
9、适用专业:计算机科学与技术
课程的性质与任务
通过本课程的学习,使学生基本掌握 MySQL 从入门到实际应用所必备的知识,课程既包括理论讲解,也包括大量实践操作。
数据库概述与MySQL安装篇
第1章:数据库概述
了解数据库的基本概念和分类
理解关系型数据库和非关系型数据库的区别
学习数据库系统结构
第2章:MySQL环境搭建
介绍MySQL的下载、安装和配置过程
学习登录MySQL服务器的方法及图形化管理工具的使用
SQL之SELECT使用篇
第3章:基本的SELECT语句
学习SELECT语句的基本语法和使用方法
掌握单表查询和多表查询的技巧
第4章:运算符
学习算术运算符、比较运算符和逻辑运算符的使用
练习各种运算符在实际查询中的应用
第5章:排序与分页
学习如何使用ORDER BY和LIMIT进行排序和分页
掌握复杂的排序和分页查询技巧
第6章:多表查询
学习内连接、外连接和交叉连接等多表查询方法
练习复杂多表查询的编写和优化
第7章:单行函数
学习MySQL中的单行函数及其用法
练习单行函数在查询中的应用
第8章:聚合函数
学习COUNT、SUM、AVG、MAX、MIN等聚合函数的使用
练习聚合函数在数据分析中的应用
第9章:子查询
学习子查询的概念和使用方法
练习嵌套子查询的编写和优化
SQL之DDL、DML、DCL使用篇
第10章:创建和管理表
学习CREATE TABLE、ALTER TABLE和DROP TABLE的使用
掌握表结构的设计和修改方法

第11章:数据处理之增删改
学习INSERT、UPDATE和DELETE语句的使用
练习数据的增加、修改和删除操作
第12章:MySQL数据类型精讲
学习MySQL支持的各种数据类型及其应用场景
掌握数据类型的选择和优化方法
第13章:约束
学习主键、外键、唯一约束、非空约束等的使用
练习约束在数据完整性保障中的应用
其它数据库对象篇
第14章:视图
学习视图的创建、修改和删除方法
掌握视图在数据抽象和安全控制中的应用
第15章:存储过程与函数
学习存储过程和函数的创建、调用和调试方法
练习存储过程和函数在复杂业务逻辑实现中的应用
第16章:变量、流程控制与游标
学习变量声明和使用、条件控制和循环控制语句的使用
练习游标在逐行处理数据中的应用
第17章:触发器
学习触发器的创建、修改和删除方法
掌握触发器在数据自动化处理中的应用
MySQL8新特性篇
第18章:MySQL8其它新特性
学习MySQL8的新功能和新特性,如窗口函数、公共表表达式(CTE)等
练习新特性在实际开发中的应用
MySQL高级特性篇大纲
第1章:Linux下MySQL的安装与使用
学习在Linux环境下安装和配置MySQL的方法
掌握Linux下MySQL的基本操作和管理技巧
第2章:MySQL的数据目录

学习MySQL数据目录的结构和作用
掌握数据目录的管理和维护方法
第3章:用户与权限管理
学习用户管理和权限分配的方法
掌握细粒度权限控制和安全管理技巧
第4章:逻辑架构
学习MySQL的逻辑架构和存储引擎架构
掌握不同存储引擎的特点和选择方法
第5章:存储引擎
学习InnoDB、MyISAM等存储引擎的特性和使用场景
掌握存储引擎的配置和优化方法
第6章:InnoDB数据页结构
学习InnoDB数据页的内部结构和工作原理
掌握数据页的管理和维护方法
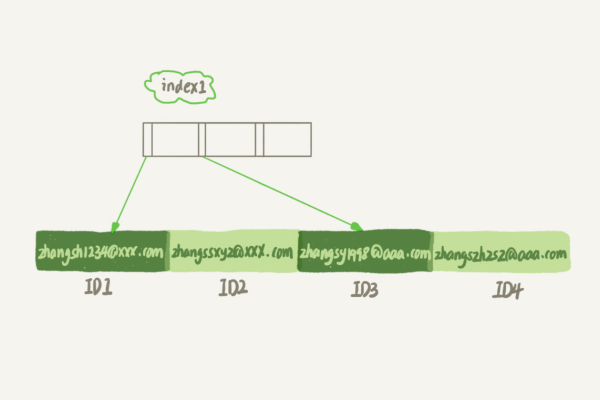
第7章:索引
学习索引的类型、创建和管理方法
掌握索引在查询优化中的应用
第8章:性能分析工具的使用
学习MySQL自带的性能分析工具,如EXPLAIN、SHOW PROCESSLIST等
掌握性能分析和问题诊断的方法
第9章:索引优化与SQL优化
学习索引优化和SQL优化的技巧和方法
练习复杂查询的优化和调优技巧
第10章:数据库的设计规范
学习数据库设计的基本原则和规范
掌握规范化设计和反规范化设计的方法和技巧
第11章:数据库其他调优策略
学习数据库的其他调优策略,如缓存、分区等

掌握综合调优的方法和技巧
事务篇
第12章:事务基础知识
学习事务的基本概念和ACID特性
掌握事务的使用方法和注意事项
第13章:MySQL事务日志
学习MySQL的事务日志类型和作用
掌握事务日志的管理和维护方法
第14章:锁
学习MySQL的锁机制和类型
掌握锁的使用和管理方法
第15章:多版本并发控制(MVCC)
学习MVCC的原理和实现方法
掌握MVCC在并发控制中的应用
日志与备份篇
第16章:其它数据库日志
学习MySQL的其他日志类型,如错误日志、慢查询日志等
掌握日志的分析和管理方法
第17章:主从复制
学习MySQL的主从复制原理和配置方法
掌握主从复制的管理和故障排除技巧
第18章:数据库备份与恢复
学习MySQL的备份和恢复方法,如物理备份、逻辑备份等
掌握备份策略和恢复技巧
适合人群
1、MySQL数据库初学者:建议按照顺序从基础篇开始学习。
2、从事后台开发(Java、Python、GO、PHP等)、MySQL开发1~3年的开发人员和运维人员:可选择基础篇部分内容学习,或直接从高级特性篇开始。
3、有资历的MySQL DBA:本课程可以作为“案头书”,在解决问题时参考。
| 序号 | 课程内容 | 教学目标 | 教学方法 | 教学时间 |
| 1 | MySQL简介 | 了解MySQL的基本概念、特点和应用场景 | 讲授法、案例分析法 | 2课时 |
| 2 | MySQL环境搭建 | 学习如何安装和配置MySQL服务器 | 演示法、实践操作 | 2课时 |
| 3 | 数据库基本概念 | 掌握数据库、表、字段、记录等基本概念 | 讲授法、图示法 | 2课时 |
| 4 | 数据库设计原则 | 学习数据库设计的基本原则和方法 | 讲授法、案例分析法 | 2课时 |
| 5 | 数据类型 | 熟悉MySQL中的各种数据类型及其特点 | 讲授法、代码示例 | 2课时 |
| 6 | 表结构设计 | 学习如何设计合理的表结构 | 讲授法、设计讨论 | 2课时 |
| 7 | 索引 | 掌握索引的概念、类型及其优缺点 | 讲授法、案例分析 | 2课时 |
| 8 | 数据库操作 | 学习如何创建、删除、修改数据库和表 | 实践操作、代码编写 | 2课时 |
| 9 | 数据插入与查询 | 熟练使用SELECT语句进行数据查询 | 讲授法、代码编写 | 4课时 |
| 10 | 数据更新与删除 | 学习如何使用UPDATE和DELETE语句进行数据更新和删除 | 讲授法、代码编写 | 2课时 |
| 11 | 子查询 | 掌握子查询的概念和使用方法 | 讲授法、代码示例 | 2课时 |
| 12 | 数据库事务 | 学习事务的概念、ACID原则及事务控制语句 | 讲授法、代码示例 | 2课时 |
| 13 | 视图与存储过程 | 掌握视图和存储过程的基本概念和操作 | 讲授法、代码编写 | 4课时 |
| 14 | 触发器与事件 | 学习触发器和事件的概念、类型及其应用 | 讲授法、代码示例 | 2课时 |
| 15 | MySQL安全性 | 了解MySQL的安全机制和配置方法 | 讲授法、实践操作 | 2课时 |
| 16 | MySQL备份与恢复 | 学习MySQL的备份和恢复方法 | 讲授法、实践操作 | 2课时 |
| 17 | MySQL性能优化 | 掌握MySQL的性能优化技巧和方法 | 讲授法、案例分析 | 2课时 |
| 18 | MySQL高级特性 | 了解MySQL的高级特性,如分区、分区表等 | 讲授法、代码示例 | 2课时 |
| 19 | MySQL与Python集成 | 学习如何使用Python操作MySQL数据库 | 讲授法、代码编写 | 2课时 |
| 20 | 课程归纳与复习 | 归纳课程内容,进行复习和巩固 | 讲授法、讨论法 | 2课时 |
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/7617.html