企业或个人建网站步骤有哪些(自己如何建企业网站)

建网站步骤包括:确定网站目的、选择域名和主机、设计网站布局、开发网站内容、测试网站功能、优化SEO、发布上线。
在数字化时代,拥有一个企业网站已经成为商业成功的关键因素之一,一个企业网站不仅可以提升品牌形象,还能作为产品或服务的在线展示平台,如何建立自己的企业网站呢?以下是详细的步骤和技术介绍:
1. 确定网站建设目的
在开始之前,明确网站的目的和目标受众至关重要,这将帮助你决定网站的内容、设计和功能。
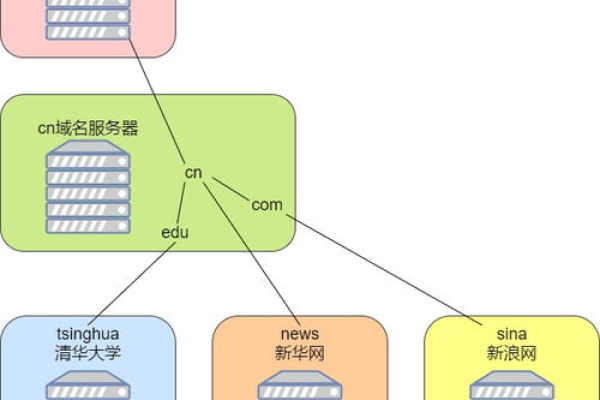
2. 选择域名和主机
选择一个简单易记且与你的企业相关的域名,选择一个可靠的网站托管服务,确保网站的稳定性和速度。
3. 规划网站结构
规划网站的布局和结构,包括页面层级、导航菜单以及每个页面的大致内容。
4. 设计网站外观
设计一个专业且符合品牌形象的网站外观,这包括颜色方案、字体选择、图片和图标等。
5. 开发网站
根据规划的结构,开始编写代码或使用网站建设工具来构建网站,确保网站在各种设备上都能良好显示。
")
HTML/CSS/JavaScript
学习基础的前端编程语言,如HTML、CSS和JavaScript,可以手动定制网站。
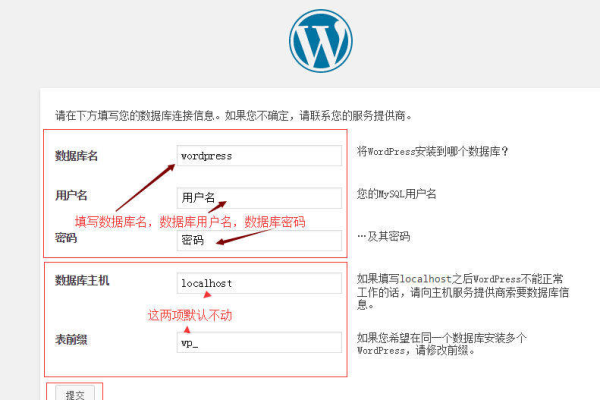
网站建设平台
使用如WordPress、Wix或Squarespace这样的网站建设平台,可以通过拖放界面快速搭建网站。
6. 添加内容
创建高质量的内容,包括文本、图片、视频等,确保内容对搜索引擎优化(SEO)友好。
7. 测试网站
在不同的浏览器和设备上测试网站,确保所有链接有效,加载速度快,没有错误或问题。
8. SEO优化
对网站进行搜索引擎优化,以提高在搜索引擎中的排名,这包括关键词研究、元标签优化、内容优化等。
9. 发布网站
一旦测试无误,就可以将网站发布到互联网上,确保定期更新内容和维护网站。
10. 分析和改进
")
使用网站分析工具,如Google Analytics,来跟踪访问者的行为,根据数据不断改进网站。
相关问题与解答
Q1: 我没有任何编程知识,是否还能建立自己的企业网站?
A1: 当然可以,有许多用户友好的网站建设平台提供拖放界面,无需编程知识也能建立网站,WordPress、Wix和Squarespace都是很好的选择。
Q2: 网站建设完成后,我需要定期更新什么内容?
A2: 定期更新内容包括博客文章、产品信息、新闻公告、成功案例等,以保持网站的活跃度和吸引访问者。
Q3: 我应该如何优化我的网站以提高搜索引擎排名?
A3: 优化网站的SEO包括使用合适的关键词、优化标题和描述、提高网站的加载速度、构建内部链接和使用社交媒体等。
Q4: 为什么我的企业需要一个网站?
A4: 网站是企业的在线门户,可以提高品牌知名度,展示产品和服务,与客户互动,并作为一个24/7的营销工具。
建立企业网站是一个涉及规划、设计、开发、内容创建和优化的过程,通过上述步骤,即使是没有技术背景的人也可以建立一个专业的企业网站,随着网站的上线,持续的维护和优化是确保网站成功的关键。







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12