一个虚拟主机绑定多个网站(一个虚拟主机绑定多个网站怎么弄)

一个虚拟主机可以通过配置多个域名和子目录来绑定多个网站,实现方法包括使用服务器的配置文件设置或通过控制面板添加域名。
在网络托管服务中,一个常见的需求是在一个单一的虚拟主机上绑定多个网站,这种做法不仅可以节省成本,还可以方便管理,下面是如何实现这一目标的详细技术介绍:
了解虚拟主机
虚拟主机(Virtual Host)是一种将单一的物理服务器通过软件技术分割成多个独立运行的小服务器的机制,每个小服务器都可以拥有自己的域名、网站内容、电子邮件系统等,就像是一个独立的服务器一样。
绑定多个网站的准备工作
1、确认你的虚拟主机计划支持多站点托管:并非所有的虚拟主机计划都支持绑定多个网站,在开始之前,你需要确认你的托管服务提供商是否支持这项功能。
2、获取所需的域名:每个网站都需要一个独立的域名,如果你打算在同一个虚拟主机上托管多个网站,你必须为每个网站购买或已经拥有一个独特的域名。
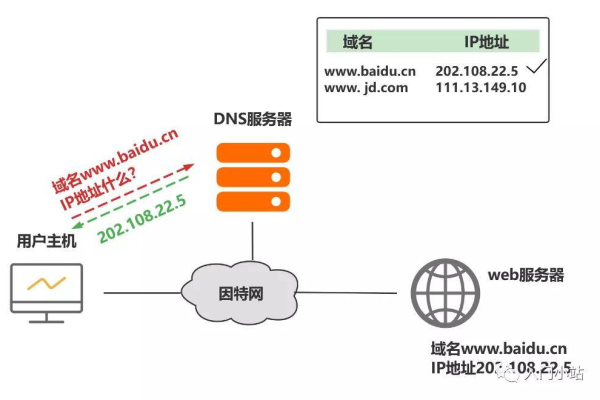
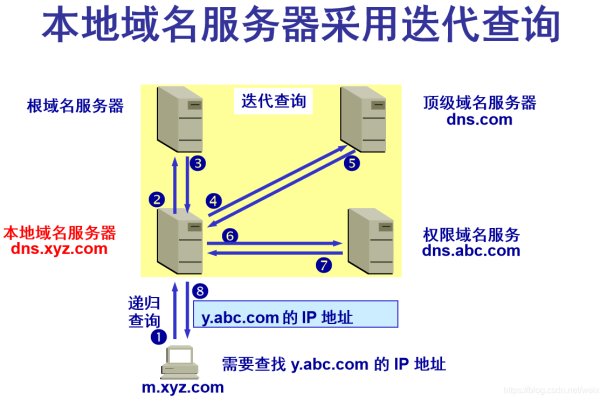
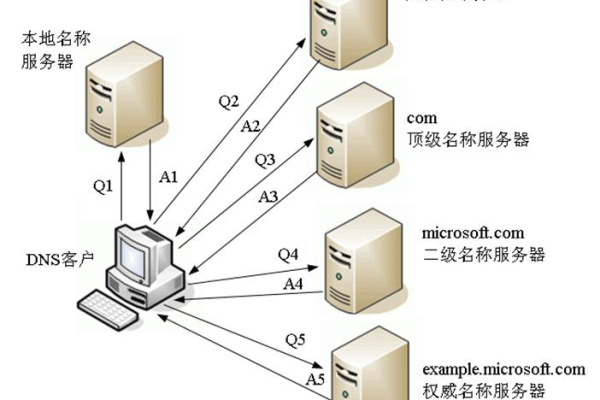
3、更新域名解析:将每个域名的DNS记录指向你的虚拟主机服务器的IP地址,这通常是通过域名注册商的控制面板完成的。
配置虚拟主机以支持多站点
接下来,我们将介绍两种常用的方法来配置虚拟主机以支持多个网站:
使用基于名称的虚拟主机(Name-based Virtual Hosting)
")
这是最常见的方法,它依赖于HTTP请求头中的Host字段来确定访问者想要访问的网站。
1、编辑配置文件:通常,你需要编辑Apache或Nginx的配置文件(例如httpd.conf或nginx.conf)。
2、设置服务器块:对于每个网站,你都需要设置一个服务器块(server block),指定域名、文档根目录和其他相关配置。
3、重启服务:修改配置后,需要重启web服务器以使更改生效。
使用基于IP的虚拟主机(IP-based Virtual Hosting)
这种方法涉及为每个网站分配一个独立的IP地址。
1、分配IP地址:确保你有足够多的IP地址可以分配给每个网站。
2、配置服务器:在服务器配置文件中为每个IP地址创建一个服务器配置部分。
")
3、调整防火墙规则:可能需要调整防火墙规则以允许对新IP地址的访问。
注意事项
1、确保备份配置文件,在进行任何更改之前创建恢复点。
2、测试配置,确保所有网站在更改后都能正常访问。
3、监控资源使用情况,确保不会因为托管多个网站而导致资源超出限制。
相关问题与解答
Q1: 如果我想在一个虚拟主机上添加更多的网站,我需要注意什么?
A1: 确保你的托管计划允许添加更多网站,并且你的服务器资源足以支持额外的负载,记得更新和测试新添加的网站配置。
")
Q2: 我是否需要为每个网站获取单独的SSL证书,如果它们在同一个虚拟主机上?
A2: 是的,即使你的网站共享同一个虚拟主机,每个网站也应该有自己的SSL证书以保证安全性。
Q3: 如果我的虚拟主机不支持多站点托管,我应该怎么办?
A3: 你可以考虑升级到更高级的托管计划,或者寻找支持多站点托管的托管服务提供商。
Q4: 使用基于名称的虚拟主机与基于IP的虚拟主机有什么区别?我应该选择哪种方式?
A4: 基于名称的虚拟主机允许你在同一IP地址上托管多个网站,而基于IP的虚拟主机则需要为每个网站分配一个独立的IP地址,大多数情况下,基于名称的虚拟主机是更实用的选择,因为它不需要额外的IP地址,并且更加容易配置,除非你有特别的理由需要不同的IP地址,否则推荐使用基于名称的虚拟主机。
通过上述步骤和注意事项,你应该能够成功地在一个虚拟主机上绑定并运行多个网站,记得在进行任何重大更改时始终遵循最佳实践,包括备份和测试,以确保网站的稳定运行。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11