如何定位WordPress数据库的实际存储位置?

在探索WordPress的数据库位置之前,了解其重要性以及如何访问和配置是至关重要的,WordPress是一个强大的内容管理系统,它使用MySQL作为数据库管理系统来存储所有网站数据,了解数据库的位置及其结构可以帮助用户更有效地管理和优化他们的网站。
WordPress数据库的位置
1、数据库服务器位置
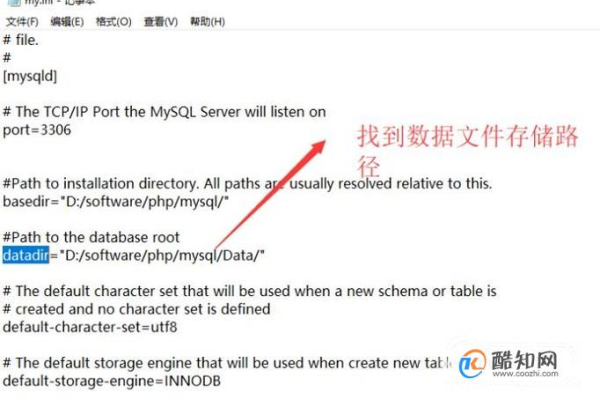
物理路径:对于拥有VPS主机或专用服务器的用户,数据库文件通常存放在服务器的文件系统中,根据不同的服务器配置,MySQL数据库一般位于/var/lib/mysql/your_database_name 目录中。
无法访问的情况:在共享主机环境中,由于安全和资源管理的考虑,数据库文件的物理路径通常是不可访问的,在这种情况下,用户需要通过其他方式,如phpMyAdmin等工具,来间接管理和访问数据库。
2、配置文件中的数据库参数
wp-config.php:WordPress的数据库配置信息存储在根目录下的wp-config.php 文件中,这个文件包含了数据库的名称(DB_NAME)、用户名(DB_USER)和密码(DB_PASSWORD)等重要信息。
查看方法:用户可以通过FTP或SSH等方式登录到网站服务器,然后直接查看wp-config.php 文件的内容,从而获取数据库的相关配置信息。
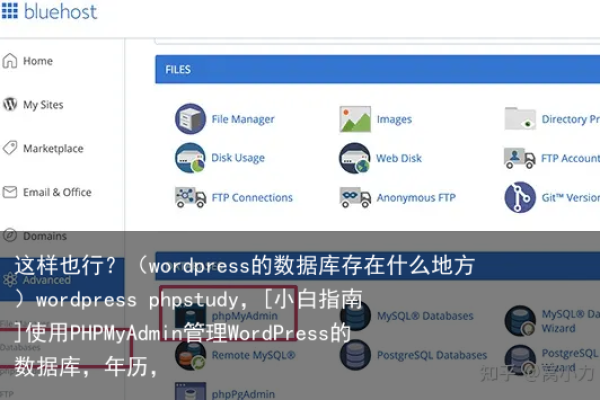
3、通过phpMyAdmin访问
登录phpMyAdmin:大多数WordPress托管服务提供phpMyAdmin工具,允许用户通过Web界面访问和管理MySQL数据库,通过主机控制面板登录phpMyAdmin,可以查看到所有的数据表,并进行管理和维护工作。
类型与功能
WordPress站点的数据不仅包括文章和页面内容,还涵盖用户信息、插件设置、主题自定义选项等,这些数据被存储在MySQL数据库中,使网站能够正常运行并保存各类更改信息。
除了以上内容,以下还有相关的常见问题及解答:
Q1: 修改wp-config.php文件安全吗?
A1: 修改wp-config.php 文件来更改数据库配置是可以的,但必须非常小心,错误的设置可能导致网站无法运行,始终建议先备份文件和数据库再进行任何修改。
Q2: 如何保证WordPress数据库的安全?
A2: 保证数据库的安全可以通过多种方式实现,例如定期更新WordPress核心和插件来防止SQL注入攻击,使用复杂的用户名和密码,以及定期备份数据库。
了解WordPress数据库的位置及其配置方式对于有效管理和优化WordPress网站至关重要,无论是通过物理路径访问数据库文件,还是通过wp-config.php 文件和phpMyAdmin工具管理数据库,正确的操作和安全措施都是确保网站平稳运行的关键。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/75638.html