如何利用MySQL学习网站进行迁移学习?

1、自学SQL网:这个网站非常适合初学者,内容由浅入深地介绍了 SQL 的基础知识,每一章都配有相应的练习,帮助用户巩固所学知识。
2、LintCode:适合零基础的用户从0到1学习 SQL,它不仅提供知识点梳理,还有针对性的刷题练习。
3、牛客网:界面美观、交互友好,适合免费刷题,每道题后面都有详细的题解与讨论,有助于深入学习。
4、leetcode力扣网:虽然不免费,但用户体验好,每道题后有大量的讨论和题解,非常适合深入学习。
5、SQLStudio:无需配置安装,官网下载后直接使用,时尚简约且默认中文,非常适合新手在实战中演练和课程设计中的练习。

6、宝藏文档网站:基于 MySQL 5.7 官方文档译制,翻译准确度较高,支持站内搜索,持续维护。
7、菜鸟教程:适合小白学习 SQL 的基础教程,目录清晰,循序渐进。
8、C语言中文网:出品的 MySQL 教程详细且深入,适合有一定基础的学习者。
9、实验楼:可以边学边做,特别适合想体验 Linux 环境的同学。

10、MySQL Tutorialspoint:由 Tutorials 创建,涵盖从基本概念到高级应用的各个方面。
以下是两个关于MySQL学习网站的常见问题及其解答:
问题1:哪个网站最适合完全零基础的初学者?
答:对于完全零基础的初学者,自学SQL网是一个非常好的选择,该网站的内容由浅入深,逐步引导用户了解 SQL 的基本概念和操作,每一章节都配备了相应的练习,让用户可以在实际操作中巩固所学的知识,通过这种方式,初学者可以逐步建立起对 SQL 的理解和应用能力。

问题2:如果我想在实际项目中应用MySQL,应该选择哪个学习网站?
答:如果你想在实际项目中应用 MySQL,推荐你访问 udemy 网站,udemy 提供了多个与 MySQL 相关的项目结合的课程,这些课程不仅涵盖了 MySQL 的基础知识,还包括如何在实际项目中应用这些知识,通过这些课程,你可以学习到如何在真实场景中使用 MySQL,从而提升你的实际项目开发能力。
选择合适的学习网站和方法对于掌握 MySQL 至关重要,无论你是初学者还是希望深入研究的开发者,上述推荐的资源都能帮助你达到学习目标,重要的是保持持续学习和实践,这样才能不断提升自己的技能水平。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/7447.html
相关文章
-

以下几个疑问句标题可供选择,,MySQL 数据库如何进行迁移?数据库迁移服务该怎样使用?,MySQL 数据库的迁移该怎么做?如何使用数据库迁移服务?,怎么对 MySQL 数据库进行迁移?数据库迁移服务应如何使用?
-
如何选择合适的数据库进行迁移学习?
-
MySQL学习与迁移,如何有效运用迁移学习提升数据库技能?
-
探索MySQL学习之旅,如何通过迁移学习提升数据库技能?
-
如何有效利用论坛资源进行网络技术迁移学习?
-
如何在MySQL中实现迁移学习?
-
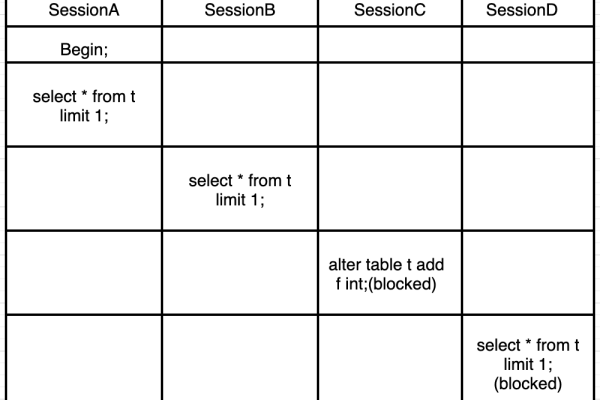
以下几个疑问句标题可供选择,,如何查看 RDS for MySQL 数据库死锁日志及 MySQL 表格字段相关问题解析,RDS for MySQL 死锁日志怎么查看?与 MySQL 表格字段操作探讨,怎样查看 RDS for MySQL 数据库的死锁日志?关于 MySQL 表格字段的思考,RDS for MySQL 数据库死锁日志查看方法与 MySQL 表格字段研究,如何查看 RDS for MySQL 数据库死锁日志?对 MySQL 表格字段的分析
-
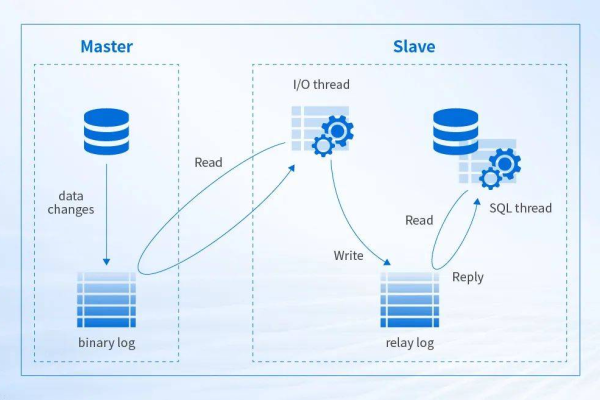
如何通过MySQL学习视频掌握数据库迁移技巧?
