如何确认Windows 11操作系统是否已永久激活?

在确保您的Windows 11(Win11)系统安全和功能齐全的过程中,验证其激活状态是一个关键的步骤,激活Windows系统是微软确保用户使用正版软件的一种方式,同时也使用户能够享受微软提供的各种服务和更新,下面将深入探讨如何检查您的Win11系统是否已经永久激活,并为您提供一些相关的扩展信息,具体分析如下:
1、通过命令提示符检查激活状态
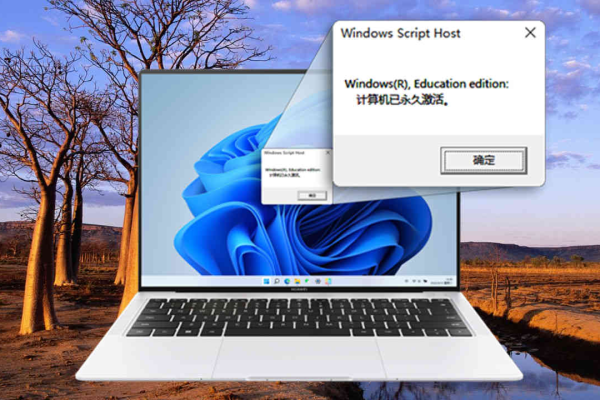
步骤描述:通过使用Windows内置的命令行工具slmgr.vbs,您可以轻松地检查激活状态,这个程序允许您通过简单的命令行操作获取激活信息。
操作方法:右键点击桌面左下角的“Windows徽标”,选择“运行”,然后输入slmgr.vbs xpr命令,执行后,如果弹出的对话框显示“计算机已永久激活”,则表示您的系统已经永久激活。
2、通过系统“设置”查看激活状态
步骤描述:Windows设置菜单中提供了一个直观的方式来检查您的系统是否激活,以及具体的激活类型和产品密钥信息。

操作方法:打开“设置”,进入“系统” > “,在这里您可以找到有关设备的具体信息,包括操作系统的版本、激活状态以及产品密钥,如果显示为“Windows已激活”,您可以进一步点击“产品密钥和激活”获取更详细的信息。
3、通过“运行”对话框检查激活期限
步骤描述:除了检查是否永久激活,了解系统的激活期限也同样重要,特别是对于那些可能只是临时激活的系统。
操作方法:与检查永久激活相似,您可以通过运行slmgr.vbs xpr命令来查看激活的截止日期,如果没有显示截止日期,通常意味着系统是永久激活的。
4、通过任务栏快速访问

步骤描述:对于经常需要检查激活状态的用户,了解一种快捷的方法是非常有用的。
操作方法:简单地按Win键或点击任务栏上的开始图标,然后进入“设置”>“系统”>“,即可快速查看激活状态而无需复杂的步骤。
在了解以上内容后,以下还有一些其他注意事项:
保持系统更新:定期检查和安装Windows更新不仅能保证系统的安全性,还有助于改善系统性能和稳定性。
使用正版密钥:始终使用正版的产品密钥进行系统激活,以避免可能的法律风险和安全隐患。

您可以便捷地确认您的Win11系统是否已经实现永久激活,这些方法不仅简单高效,也确保您可以充分利用您的系统,享受微软提供的所有服务与支持。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12