如何有效利用防御CDN来增强网站安全?

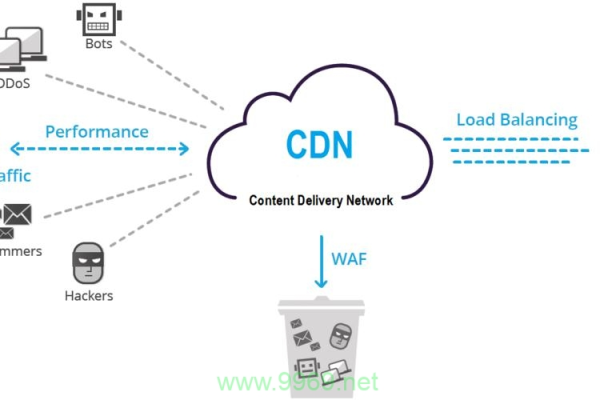
防御CDN(Content Delivery Network)是一种基于云计算的网络安全解决方案,旨在提高网站的可用性和性能,同时减少网络攻击对网站的影响,以下是对防御CDN的具体介绍:
1、技术原理
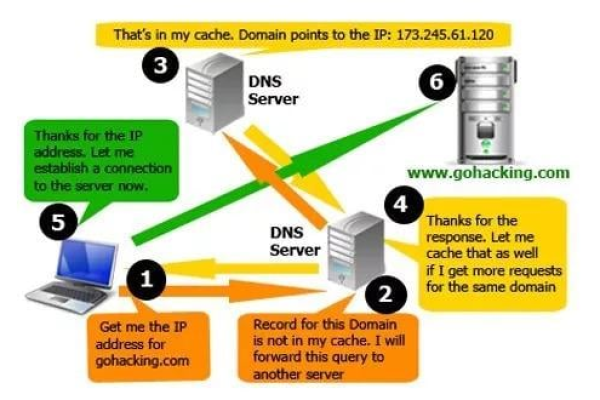
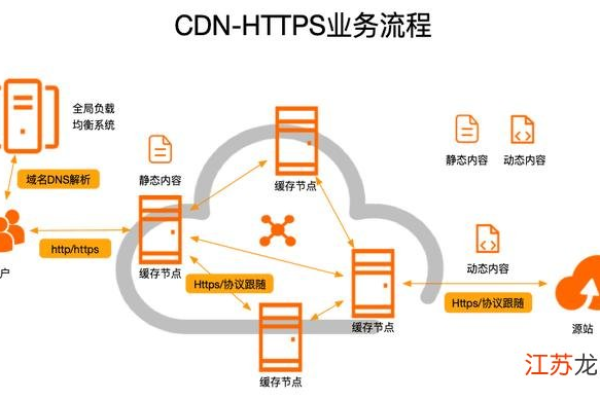
内容分发:通过在全球范围内部署多个节点,将网站内容缓存到这些节点上,从而加速网站内容的传输速度。
智能调度:根据用户的地理位置和请求,自动选择最近的节点来提供服务,提高响应速度和性能。
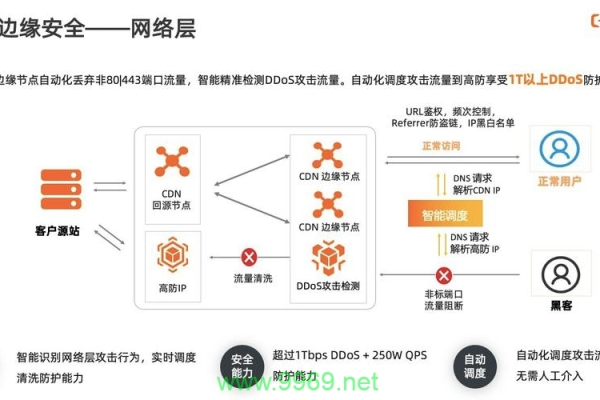
负载均衡:通过分散DDoS等攻击流量到各地的节点,降低源服务器和节点的压力,提高网站的稳定性。
2、防御原理
流量清洗:通过检测和清洗异常流量,如DDoS攻击、CC攻击等,保证网站的正常运行。
IP黑白名单:设置允许或禁止访问的IP地址列表,限制对重要资源的访问。
安全协议:使用加密技术对数据进行保护,确保数据的安全性和机密性。

3、优点
加速网站速度:通过全球分布的节点,显著提高网站的加载速度和用户体验。
提高网站可用性:在遭受攻击时仍能保持网站的正常运作,减少停机时间。
降低运营成本:按需付费的方式降低了企业的运营成本。
4、应用场景
网站加速:提高网站的响应速度和性能,适用于访问量较大的网站。

下载加速:加速大型文件或多个文件的传输速度。
云服务:为云中部署的应用程序和数据提供安全、快速的访问。
5、未来发展趋势
AI和机器学习整合:利用人工智能和机器学习技术来更好地识别和应对网络威胁。
全球化扩张:扩展更多地区,确保全球用户的安全和高速访问。
更强大的安全性特性:提供更多高级安全性特性,如Web应用程序防火墙、载入检测系统等。

多云策略集成:集成多云策略,以确保数据的高可用性和冗余性。
高度可定制性:用户可以选择各种安全性和性能选项,以适应其特定的应用程序和业务需求。
持续监控和分析:注重持续监控和分析,以便及时发现和解决安全威胁。
强化边缘计算:强化边缘计算能力的高防CDN将提供更高效和低延迟的防护服务。
防御CDN作为一种有效的网络安全解决方案,不仅能够提高网站的访问速度和可用性,还能有效地抵御各种网络攻击,随着技术的不断发展,防御CDN将在智能化、全球化、安全性和定制性等方面取得更大的进展,为用户提供更加全面和高效的网络安全服务。
| 特征 | 防御CDN |
| 定义 | 防御CDN(Content Delivery Network)是一种网络技术,通过在多个地理位置部署服务器来缓存网站内容,以提高访问速度和安全性。 |
| 目的 | 1. 提高网站访问速度 2. 提高网站安全性 3. 减轻源服务器压力 |
| 工作原理 | 1. 用户访问网站时,首先连接到最近的服务器获取内容。 2. 服务器缓存网站内容,以便快速响应用户请求。 3. 防御CDN通过检测反面流量,如DDoS攻击,并将其重定向到其他服务器或丢弃,以保护网站免受攻击。 |
| 功能 | 1.:缓存静态资源,如图片、CSS和JavaScript文件,减少源服务器的负载。 2.负载均衡:将流量分配到多个服务器,确保网站在高流量下稳定运行。 3.DDoS防护:检测和防御分布式拒绝服务(DDoS)攻击。 4.Web应用防火墙(WAF):防止反面攻击,如SQL注入、跨站脚本(XSS)等。 5.SSL/TLS加密:提供安全的连接,保护用户数据。 |
| 优势 | 1. 提高网站访问速度和用户体验。 2. 降低源服务器的带宽成本。 3. 提高网站安全性,防止反面攻击。 4. 支持全球化部署,满足不同地区的用户需求。 |
| 劣势 | 1. 需要一定的投资和运营成本。 2. 可能存在缓存不一致的问题。 3. 需要配置和优化,以充分发挥其性能。 |


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01