网络设置第二个路由器怎么设置

什么是网络设置第二个路由器?
网络设置第二个路由器,是指在家庭或办公环境中,通过将一台路由器连接到已有的网络中,从而实现多个路由器共同为设备提供网络服务的过程,这种设置通常用于扩大网络覆盖范围、增加网络带宽或者实现网络分流等目的。
如何设置网络设置第二个路由器?
1、确认网络环境
在设置第二个路由器之前,需要先了解当前网络环境,包括已有路由器的型号、无线设置、LAN口数量等信息,这有助于确定新路由器的功能和配置。
2、选择合适的路由器
根据网络环境和需求,选择合适的路由器,有线路由器适合较远距离的扩展,而无线路由器则适用于近距离的覆盖,还需要考虑路由器的性能、价格等因素。
3、配置主路由器

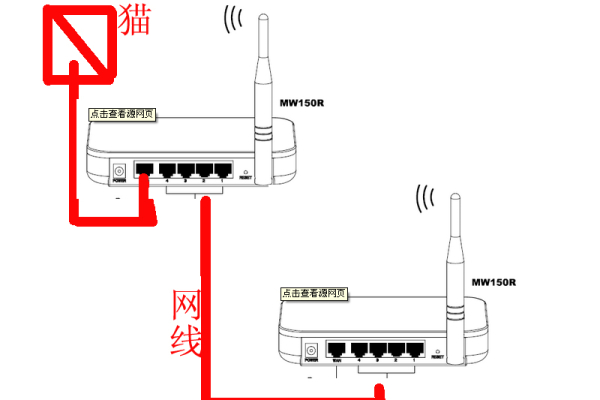
将新购买的路由器连接到已有网络中,通常需要将其WAN口连接到主路由器的LAN口,登录新路由器的管理界面,修改其IP地址、SSID等参数,使其与主路由器不同,接下来,需要设置无线信道、加密方式等无线参数。
4、配置子路由器
在新路由器的管理界面中,找到“DHCP服务器”或“IP地址分配”等功能,将其关闭或设置为不分配IP地址,这样可以避免新路由器与主路由器产生冲突,接着,根据需要设置子路由器的其他参数,如端口转发、负载均衡等。
5、重启路由器
完成上述设置后,重启新旧两个路由器,使更改生效,此时,新路由器应该能够正常工作,并与其他设备共享网络资源。

网络设置第二个路由器的优点有哪些?
1、提高网络覆盖范围:通过设置第二个路由器,可以扩大家庭或办公室的无线网络覆盖范围,使更多设备能够接入网络。
2、增加网络带宽:如果主路由器的带宽不足以满足所有设备的需求,可以通过设置第二个路由器实现负载均衡,提高整体网络速度。
3、实现网络分流:一个网络接口可能无法承受过多的流量,此时,可以通过设置第二个路由器将部分流量分流到其他接口,减轻主接口的压力。
4、增强网络安全性:通过设置多个路由器,可以实现网络隔离和防火墙功能,提高整个网络的安全性和稳定性。
如何解决设置第二个路由器时可能遇到的问题?
1、新路由器无法上网:检查新路由器的连接状态和无线设置,确保其与主路由器在同一局域网内,尝试重启新旧两个路由器。

2、新路由器无法识别主路由器:登录新路由器的管理界面,检查DHCP服务器功能是否关闭或未正确配置,还可以尝试将新路由器的IP地址更改为主路由器的一个未使用的地址。
3、新旧两个路由器信号干扰:为了避免信号干扰,建议将新旧两个路由器放置在不同的位置,或者使用金属屏蔽罩隔离它们之间的信号。
4、新旧两个路由器无法实现负载均衡:检查新旧两个路由器的负载均衡功能是否正确配置,如果仍然无法实现负载均衡,可以考虑升级设备的固件或者更换更高性能的路由器。








热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01