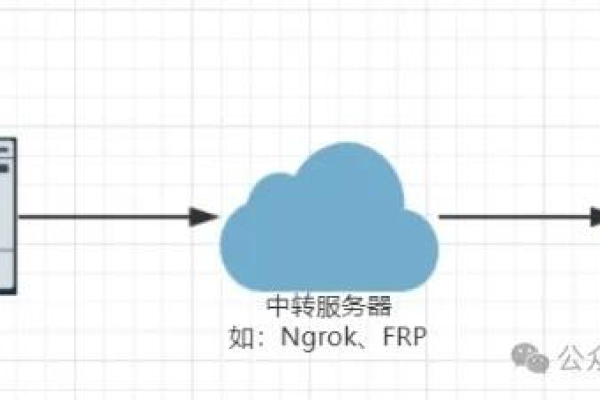
猕猴桃cdn 内网ip

猕猴桃CDN(Content Delivery Network,内容分发网络)是一种利用分布式服务器来加速内容传输的技术,它通过将内容缓存到离用户更近的节点上,从而减少数据传输的延迟和带宽消耗,提高用户体验,在猕猴桃CDN中,内网IP地址扮演着重要的角色,它们用于在内部网络中标识和定位不同的服务器或设备。
猕猴桃CDN与内网IP的关系
1、内网IP的作用:在猕猴桃CDN系统中,内网IP主要用于在局域网内部识别和定位不同的服务器或设备,这些内网IP地址通常由路由器或网络设备分配给连接到网络的设备。
2、猕猴桃CDN的配置:为了配置猕猴桃CDN,用户需要将其客户端ID(client_id)提交到官方网站,并在本地计算机上创建相应的缓存目录,这些缓存目录将用于存储从CDN节点下载的内容,在配置过程中,用户还需要确保路由器开启了UPNP(Universal Plug and Play,通用即插即用)或DMZ(Demilitarized Zone,非军事区)功能,以便猕猴桃CDN能够正常工作。
3、内网IP的重要性:内网IP对于猕猴桃CDN的性能和稳定性至关重要,如果内网IP配置不正确或无法访问,可能会导致CDN服务无法正常工作或性能下降,在配置猕猴桃CDN时,用户需要仔细检查内网IP的配置情况,并确保其正确无误。
表格:猕猴桃CDN配置步骤与内网IP关系
| 步骤 | 描述 | 与内网IP的关系 |
| 1 | 下载并安装猕猴桃CDN客户端 | 客户端需要在内网IP对应的设备上运行 |
| 2 | 获取并提交client_id | client_id与内网IP绑定的设备相关联 |
| 3 | 创建缓存目录 | 缓存目录通常位于内网IP对应的设备存储空间中 |
| 4 | 配置路由器UPNP或DMZ | 确保内网IP可以通过路由器被外部访问 |
| 5 | 启动猕猴桃CDN服务 | 服务将使用内网IP进行通信和数据传输 |
FAQs
1、问:如何查看设备的内网IP地址?
答:在Windows系统中,可以通过打开命令提示符并输入ipconfig命令来查看设备的内网IP地址,在Linux系统中,可以使用ifconfig或ip a命令来查看。
2、问:如果内网IP地址发生变化怎么办?
答:如果内网IP地址发生变化(由于路由器重启或网络配置更改),用户需要重新配置猕猴桃CDN客户端以使用新的内网IP地址,这通常涉及更新路由器设置、重新获取client_id以及重新启动猕猴桃CDN服务。
小编有话说
猕猴桃CDN作为一种高效的内容分发技术,在提高网站访问速度和用户体验方面发挥着重要作用,而内网IP作为猕猴桃CDN系统的重要组成部分,其正确配置对于CDN服务的正常运行至关重要,希望本文能够帮助用户更好地理解猕猴桃CDN与内网IP的关系,并顺利完成CDN服务的配置和使用。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/72727.html