国内大宽带的vps租用有哪些优势和劣势

在国内大宽带的VPS租用中,有很多优势值得我们关注,大宽带VPS可以提供更高的网络速度和更稳定的连接,这对于需要大量上传和下载数据的用户来说非常重要,例如视频编辑、游戏玩家和在线办公人员等,大宽带VPS还可以支持更多的并发连接,这意味着您可以同时与更多的用户共享您的服务器资源,而不会受到性能限制。
大宽带VPS通常具有更高的内存和CPU资源,这使得它们能够更好地处理大型应用程序和服务,从而提高了运行效率,对于需要运行复杂脚本或数据库的应用来说,这是一个非常有用的优势。
第三,大宽带VPS通常提供更多的操作系统和软件选择,这意味着您可以根据自己的需求选择最适合您的操作系统和应用程序,从而更好地定制您的服务器环境,大宽带VPS还通常提供更多的备份和恢复选项,这可以帮助您确保数据的安全性和可靠性。
第四,大宽带VPS通常具有更好的技术支持和服务水平,由于它们需要提供更高的性能和稳定性,因此这些服务提供商通常会投入更多的资源来维护他们的基础设施和服务团队,这意味着当您遇到问题时,您可以更快地得到解决,并且有更多的机会获得专业的建议和指导。

在国内大宽带的VPS租用中,有很多优势可以帮助您更好地满足自己的业务需求,无论您是个人用户还是企业用户,都可以从中受益。
相关问题与解答:
问题1:什么是VPS?
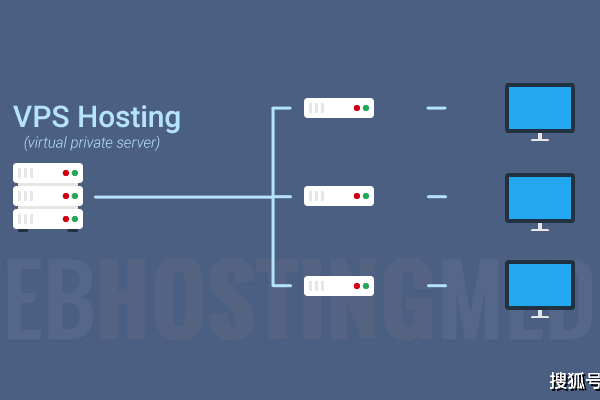
答:VPS(Virtual Private Server)虚拟专用服务器是一种基于虚拟化技术的托管服务,它允许将一台物理服务器划分为多个独立的虚拟服务器实例,每个VPS实例都有自己独立的操作系统、文件系统和资源分配,因此可以独立运行应用程序和服务。
问题2:如何选择合适的VPS租用服务?
答:在选择VPS租用服务时,您需要考虑以下几个因素:带宽、内存、CPU资源、操作系统和软件支持、备份和恢复选项、技术支持和服务水平等,根据您的具体需求和预算,选择最适合您的VPS租用服务。
问题3:大宽带VPS是否适合运行游戏?
答:是的,大宽带VPS通常具有较高的网络速度和稳定性,这对于游戏玩家来说非常重要,它们还可以支持更多的并发连接,这意味着您可以同时与更多的玩家共享服务器资源而不会受到性能限制。
问题4:如何优化VPS性能?
答:要优化VPS性能,您可以采取以下措施:升级硬件配置(如增加内存和CPU资源)、优化操作系统设置、使用缓存技术(如Redis)、限制并发连接数、定期备份数据等,保持良好的网络环境和遵守服务商的使用政策也有助于提高VPS性能。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11