
上一篇
深入理解MapReduce2,如何有效提交作业?
MapReduce2是Hadoop的升级框架,用于处理大规模数据集。它通过将作业分解为多个小任务并行处理,提高数据处理效率。提交作业时,需配置相关参数并上传至集群执行。
MapReduce2是Hadoop的一个关键组件,用于处理大规模数据集,下面将深入了解MapReduce2的作业提交流程,该流程涉及多个关键步骤,从作业的初始化到资源的请求,再到任务的执行与跟踪,具体如下:

1、初始化及配置
作业提交:通过调用Job类的submit()方法来开始提交过程,这一步会创建一个内部的JobSubmitter实例,并调用其submitJobInternal()方法来执行实际的提交。
配置和资源准备:客户端需要准备必要的配置文件(jar包和conf),并指定输入输出路径,输出路径必须不存在,以便框架能自动创建和管理这些路径。
2、资源请求与分配
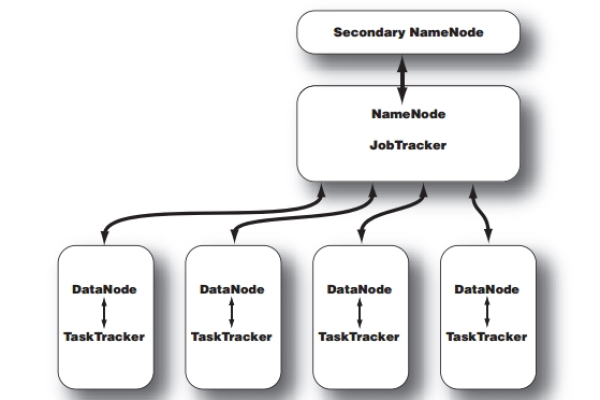
请求作业ID:作业提交后,客户端会向ResourceManager请求一个作业ID(applicationID),这个ID是作业管理的核心标识。
资源分配:ResourceManager负责资源的分配,为应用程序分配第一个container,并与对应的NodeManager通信,要求NodeManager在这个container中启动ApplicationMaster。
3、应用主节点的角色
注册与监控:ApplicationMaster首先需要在ResourceManager的应用程序管理器中注册,使其可以通过web界面监控和管理,这一步骤是确保作业可以在Yarn上被追踪和管理的关键。
资源申请:ApplicationMaster负责进一步向ResourceScheduler申请资源,根据作业的需求动态获取额外的资源。
4、计算与执行
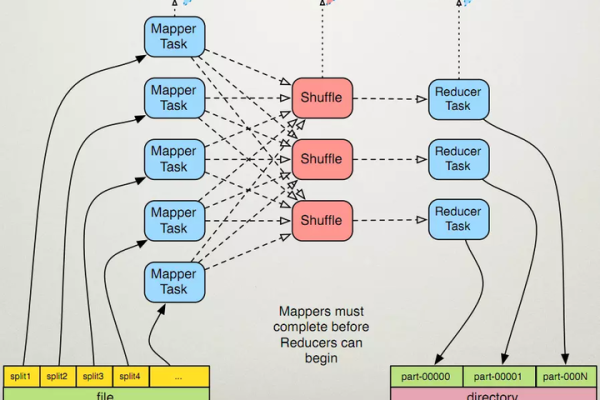
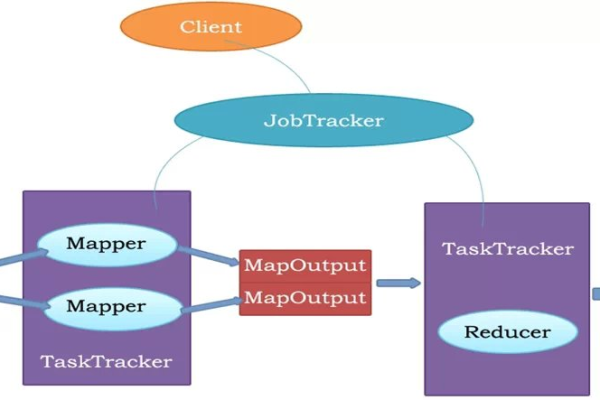
分片与格式化:输入数据源需要进行分片操作,划分为等大小的数据块(split),每个分片构建一个Map任务,分片数据被格式化为键值对的形式,供Map函数处理。
Map和Reduce任务的执行:每个Map任务处理一个分片,执行用户定义的map()函数,完成后,Reduce任务根据Map的输出进行数据的整合和输出。
5、结果收集与错误处理
进度跟踪与完成:作业提交后,客户端通过waitForCompletion()方法轮询作业的进度,并在控制台报告,作业完成后,会根据成功与否显示相应的结果或错误信息。
对于MapReduce2的提交过程,以下几点是需要特别注意的:
确保输出目录在作业运行前不存在,避免数据冲突。
正确配置和优化Map与Reduce函数,以提升作业执行的效率和质量。
监控和调整资源使用,尤其是在大型集群环境中,合理的资源管理极为关键。
MapReduce2的提交和执行是一个复杂但有序的过程,涉及从作业配置到资源请求、任务分配及执行等多个环节,理解这一流程有助于更有效地管理和调试大数据处理任务,确保数据的正确处理和资源的高效利用。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/72327.html
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
如何通过MapReduce REST API接口管理MapReduce作业?
-
kerberos提交 mapreduce_提交Mapreduce作业
-
MapReduce 实例解析,如何通过案例深入理解 MapReduce 原理?
-
MapReduce作业数量与配置MapReduce作业基线之间有何关联?
-
如何通过设置任务优先级来优化mapreduce yarn包中提交的MapReduce作业效率?
-
MapReduce编程模型如何工作,深入了解MapReduce接口的功能和用途?








