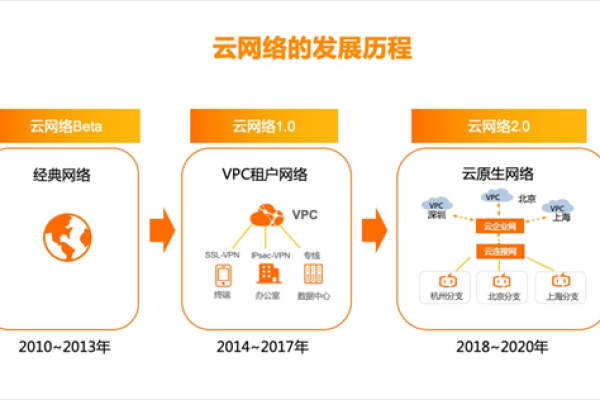
如何创建云主机,一步步流程解析

选择云服务商,注册并登录账号。进入控制台,找到云主机服务,点击创建实例。选择操作系统、配置CPU和内存,设置存储空间和网络配置。确认订单信息,完成支付。等待几分钟,云主机即创建成功。
创建云主机的流程是一个涉及多个步骤和组件的过程,以下是一个详细的创建流程:
创建云主机流程
| 步骤 | 描述 |
| 1. 登录云平台 | 用户需要首先登录到云平台的管理界面或使用命令行工具进行身份验证,这一步通常涉及到输入用户名和密码,以及可能的多因素认证。 |
| 2. 选择项目 | 在云平台上,用户需要选择一个已经存在的项目,或者创建一个新的项目来容纳即将创建的云主机。 |
| 3. 配置网络 |
|
| 4. 上传镜像 | 用户需要上传一个操作系统镜像到云平台的镜像库中,这个镜像将作为云主机启动时的模板,常见的镜像格式包括QCOW2、ISO等。 |
| 5. 创建安全组 | 为了控制云主机的网络访问权限,用户需要创建一个安全组,并定义入站和出站规则,允许SSH(端口22)和HTTP(端口80)流量。 |
| 6. 创建云主机实例 |
|
| 7. 启动云主机 | 完成上述配置后,用户可以启动云主机实例,云平台会根据配置自动分配资源并启动虚拟机。 |
| 8. 测试与验证 | 启动后,用户可以通过远程连接工具(如SSH)连接到云主机,验证其是否正常运行,并执行必要的测试任务,如ping外部网站等。 |
相关问答FAQs
问:在创建云主机时,如何选择适当的实例类型?
答:选择适当的实例类型取决于您的应用需求和预算,您需要考虑CPU、内存、存储和网络带宽等资源的需求,对于计算密集型应用,应选择具有更多CPU和内存资源的实例类型;对于存储密集型应用,则应选择具有更大存储空间的实例类型,还需要考虑成本效益,避免过度配置导致资源浪费。
问:如何更改已创建云主机的配置?
答:更改已创建云主机的配置通常涉及到修改实例类型、调整网络设置或更新镜像等操作,这些操作可以通过云平台的管理界面或API来完成,但请注意,某些更改可能需要重启云主机才能生效,且在某些情况下可能不可逆或会导致数据丢失,在进行任何更改之前,请务必备份重要数据并仔细阅读相关文档。
小编有话说
创建云主机是云计算领域的一项基础而重要的技能,通过本文的介绍,我们详细了解了从登录云平台到成功创建并启动云主机的全过程,希望这些信息能够帮助读者更好地理解和掌握云主机的创建流程,我们也鼓励读者在实践中不断探索和学习,以便更高效地利用云计算资源来满足业务需求。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/71933.html