上一篇
Kafka Client在哪些应用场景中表现出色?
KafkaClient主要用于与Kafka集群进行交互,适用于消息的生产和消费。在分布式系统中,它常用于解耦服务、缓存数据和异步通信等场景。
Kafka是一种高吞吐量的分布式发布订阅消息系统,在互联网应用中扮演着重要的角色,它主要用于构建实时数据流管道和消息队列系统,下面将深入探索Kafka客户端的各种使用场景,并说明如何在Java中使用Kafka客户端库来实现与Kafka服务器的交互。

1、实时数据处理
数据流管道构建:Kafka客户端可以用于构建实时数据流处理管道,支持高速的数据流入和流出,通过利用Kafka生产者API,可以实时收集数据并将其发布到特定的Topic中,这些数据可以是日志信息、用户行为记录或其他类型的事件数据。
低延迟消息传递:在需要快速响应的场景中,如金融交易系统或实时监控平台,Kafka客户端提供低延迟的消息发布和订阅机制,确保消息能够几乎实时地传达到消费者端。
2、日志收集与处理
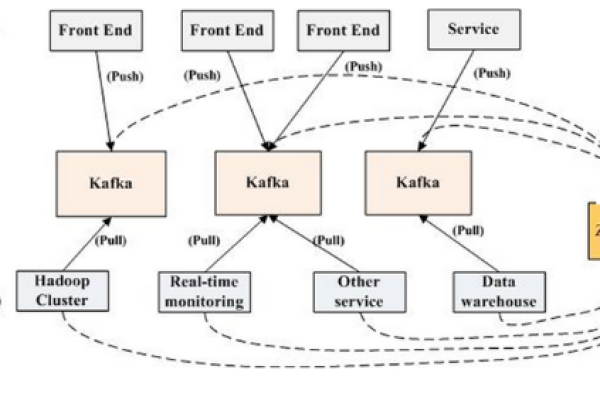
集中式日志管理:Kafka客户端常用于集成日志收集系统,将所有服务的日志集中发送到Kafka集群,再由日志处理服务消费这些数据进行解析、存储和分析。
强大的日志审计:使用Kafka客户端,可以实现强大的日志审计功能,企业可以通过对日志数据的分析,发现系统中的异常行为或性能瓶颈,及时作出调整。
3、消息队列系统
解耦合的服务间通信:在分布式系统中,Kafka客户端可以用作消息队列,支持不同服务之间的异步通信,通过这种方式,系统的各个组件可以保持独立,降低相互间的依赖性。
实现负载均衡和服务扩展:当流量增大时,Kafka客户端能够通过分区机制实现消息的负载均衡,提升系统的处理能力,这种模式也便于实现服务的动态扩展。
4、数据集成与流转
连接不同的数据源:Kafka客户端可用于从各种数据源收集信息,如数据库、日志文件和其他应用程序,通过将这些数据发送到Kafka Topic,可以实现数据的集中管理和进一步处理。
数据清洗与转换:在数据到达消费者之前,可以利用Kafka Streams等高级特性在数据流传送过程中进行清洗和转换操作,满足特定业务需求。
5、事件驱动架构和微服务
事件驱动的消息生产:Kafka客户端支持在事件驱动架构中作为事件的生产者,它可以生成事件并发送到特定的Topic,供其他服务或组件消费。
微服务之间的同步与通信:在微服务架构中,Kafka客户端扮演着服务间通信的关键角色,通过Kafka作为消息中间件,实现服务解耦和通信同步。
6、大数据处理和集成
数据湖构建:Kafka客户端可应用于大数据场景,作为构建数据湖的重要组成部分,实时采集和处理来自各种源的大量数据。
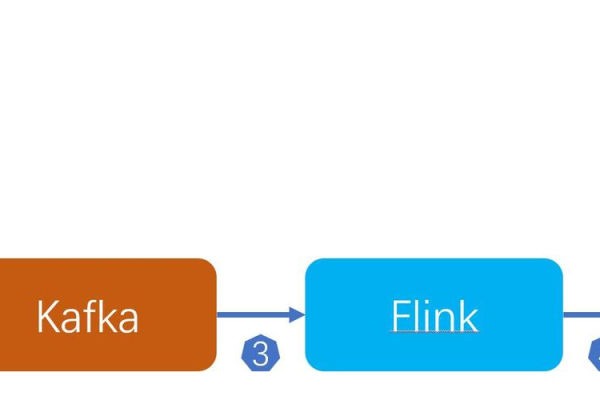
集成分析工具:Kafka客户端可以与其他大数据处理框架如Apache Flink、Spark等集成,为数据分析和机器学习提供实时数据流输入。
7、物联网(IoT)数据采集
设备数据实时收集:在物联网应用中,Kafka客户端可用于从各种传感器和设备上实时采集数据,并将这些数据发布到Kafka Topic中。
支撑海量数据流处理:由于IoT设备可能产生巨大的数据量,Kafka客户端的强大数据吞吐能力使其成为处理这些数据的理想选择。
8、复杂事件处理(CEP)
实时模式识别:Kafka客户端结合复杂的事件处理技术,能够基于流入Kafka Topic的消息进行实时模式匹配和事件识别。
多步骤事件聚合:通过Kafka Streams,客户端可以在事件通过多个处理阶段时执行复杂的聚合操作,为决策提供支持。
值得一提的是,在Java开发中,使用Kafka客户端的第一步是引入相应的kafkaclients库依赖,这可以通过在项目的构建脚本中添加对应的jar包实现,随后,开发者需要编写代码以实现生产者和消费者的具体逻辑,生产者负责创建ProducerRecord对象,指定消息所属的Topic和内容,而消费者则需要订阅指定的Topic,并进行消息的消费处理。
Kafka客户端的使用场景覆盖了从实时数据处理到大数据集成等多个方面,在Java中使用Kafka客户端,不仅需要掌握相关API的使用,同时也要考虑序列化和反序列化的要求,以及客户端库版本与Kafka集群的兼容性,了解这些基本概念和应用场景对于开发高性能、稳定的Kafka应用至关重要。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/71711.html