如何有效进行Linux总线匹配?

在Linux系统中,设备和驱动之间的匹配是一个核心环节,确保了系统能够正确识别并使用各种硬件设备,本文将深入探讨Linux总线匹配方法,涵盖平台总线的注册与匹配方式,常用总线匹配函数,以及如何添加或注销总线等关键操作,文章末尾还附有相关问答FAQs,以解答常见的疑问。
平台总线注册和匹配方式
在Linux的设备驱动模型中,总线扮演着极为重要的角色,它负责维护两个链表,记录所有已注册的平台设备和平台驱动,每当新的设备或驱动加入时,总线会调用platform_match函数进行配对,这个匹配过程是自动进行的,确保了设备和驱动之间的正确连接。
平台总线的结构体原型为platform_bus_type,位于内核源码的/driver/base/platform.c文件中,了解这一结构体对于深入理解平台总线的工作原理至关重要。
常用总线匹配函数
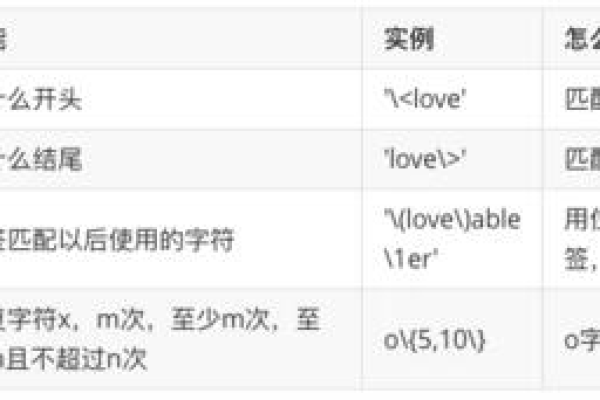
Linux系统提供了多种match匹配函数,这些函数在不同总线类型之间存在一定的差异,对于平台总线而言,platform_match函数用于匹配工作,随着技术的发展,还会有更多的匹配函数被引入,以支持不同类型的总线和设备。
添加或注销总线
虽然在大多数情况下,Linux内核已经为我们准备好了大部分的总线驱动,但系统中并不总是包含所有需要的总线,Linux提供了一些函数来添加或注销总线,允许开发者根据需要注册新的总线类型,这是一项高级操作,通常只在编写新的驱动模块或是进行深度定制时才会用到。
注册新设备
注册新设备时,主要完成两项工作:命名和指定挂载的总线,名字是总相匹配的重要依据,而正确的总线挂载则确保了设备能够在正确的总线上被识别和使用,这一过程不仅涉及到设备驱动的开发,也关系到设备管理和维护的便捷性。
相关问答FAQs
如何确定我的设备是否已经被系统识别?
可以通过查看/sys/bus目录下的内容来确认你的设备是否已被识别,每个已注册的设备都会在该目录中有一个对应的条目。
如果我想自己编写一个驱动程序,我需要了解哪些知识?
需要深入了解Linux内核编程,特别是设备驱动模型的知识,熟悉C语言和数据结构也是必要的,了解你的目标设备的工作原理和相关的总线类型同样重要。
通过以上的详细解析,我们了解了Linux系统中总线匹配方法的核心内容,包括平台总线的注册与匹配方式、常用总线匹配函数、如何添加或注销总线等关键操作,通过相关问答FAQs部分,我们也解答了一些实际开发中可能会遇到的问题,掌握这些知识对于任何希望深入了解Linux设备驱动开发的人员来说都是非常重要的。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/71576.html