
上一篇
如何编译并成功运行MapReduce应用的输入路径(inputpath)?
MapReduce应用需要先编译,然后通过指定输入路径(inputpath)来运行。编译过程确保代码无错误,而指定输入路径让程序知道从哪里读取数据进行处理,是执行MapReduce作业的基本步骤。
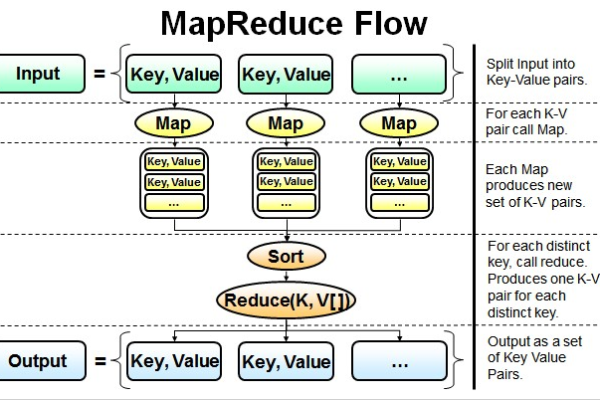
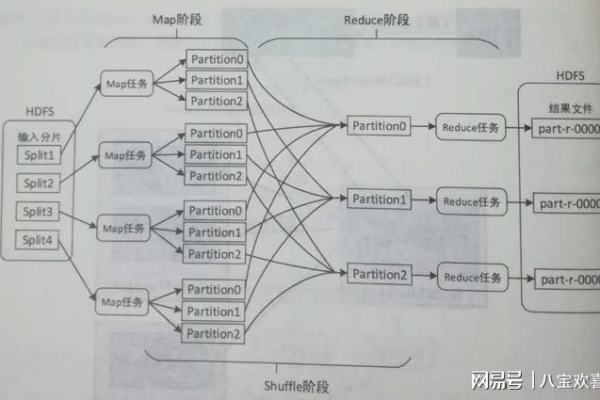
MapReduce是一种编程模型,用于处理和生成大数据集,它由两个主要阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块,然后每个块被映射到一个键值对,在Reduce阶段,所有具有相同键的键值对被组合在一起,并使用一个reduce函数进行处理。
? 第1张")
以下是一个简单的MapReduce应用示例,用于统计文本中单词的出现次数:
1、编写Mapper类:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split("\s+");
for (String w : words) {
word.set(w);
context.write(word, one);
}
}
}2、编写Reducer类:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}3、编译并运行MapReduce应用:
确保已经安装了Hadoop和Java环境,将上述代码保存为WordCountMapper.java和WordCountReducer.java文件,使用以下命令编译这两个类:
$ javac classpathhadoop classpath d wordcount_classes WordCountMapper.java WordCountReducer.java
编译成功后,会生成一个名为wordcount_classes的目录,其中包含编译后的.class文件,创建一个名为wordcount.jar的JAR包,包含所有编译后的类:
$ jar cvf wordcount.jar C wordcount_classes/ .
使用以下命令运行MapReduce作业:
$ hadoop jar wordcount.jar org.apache.hadoop.examples.WordCount input_path output_path
input_path是HDFS上存储输入数据的路径,output_path是要将结果写入的HDFS路径。
$ hadoop jar wordcount.jar org.apache.hadoop.examples.WordCount /user/hadoop/input /user/hadoop/output
运行完成后,可以在HDFS上查看output_path目录下的结果。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/71519.html
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
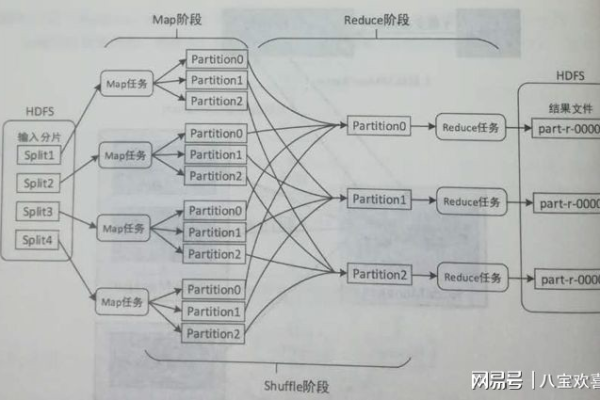
MapReduce输入输出,在MapReduce应用开发中,有哪些关键概念决定了数据的输入与输出处理流程?
-
如何编译并运行MapReduce应用程序?
-
如何在开发MapReduce应用中找到合适的mapreduce应用实例分析?
-
python 运行mapreduce_运行MapReduce作业
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
MapReduce框架在数据处理中的应用特点有哪些?如何进行MapReduce应用开发?
-
MapReduce Input 本地_INPUT,如何优化本地输入以提升数据处理效率?








