如何部署MySQL数据库?有哪些推荐的书籍可以参考?

MySQL是一种广泛使用的关系型数据库管理系统,因其开源、免费和高性能而受到许多企业和开发者的青睐,以下是关于MySQL的书籍推荐和部署指南:
1、书籍推荐
《SQL必知必会》:这本书由Ben Forta撰写,是学习SQL语言的经典入门书,它从基础的SQL语法讲起,包括数据检索、联结、子查询等基本操作,非常适合初学者快速上手,书中内容通俗易懂,通过实际示例帮助读者理解SQL的基本概念和应用。
《MySQL必知必会》:同样由Ben Forta撰写,这本书是针对MySQL数据库的定制版,介绍了MySQL特有的功能和常用操作,它涵盖了从安装到日常使用的各个方面,适合希望深入学习MySQL的读者。

《深入浅出MySQL:数据库开发、优化与管理维护(第3版)》:由唐汉明等人撰写,源自网易公司多位资深数据库专家的经验归纳,本书分为基础篇、开发篇、优化篇、管理维护篇和架构篇,内容全面且实用,适合不同层次的读者。
《高性能MySQL(第4版)》:这本书是MySQL领域的经典之作,由Peter Zaitsev等人撰写,它详细介绍了MySQL的性能优化技巧,包括索引设计、查询优化、存储引擎选择等方面的内容,对于需要处理大规模数据的开发者和DBA来说,这是一本必读的书籍。
《MySQL技术内幕:InnoDB存储引擎(第2版)》:由姜承尧撰写,深入解析了InnoDB存储引擎的内部实现,对于希望深入了解MySQL底层原理的高级用户来说,这本书提供了宝贵的知识。

2、MySQL的部署
单机部署:单机部署是最简单的一种方式,适用于小规模应用或开发测试环境,你需要在一台服务器上安装MySQL,并进行基本的配置,如设置端口号、字符集、时区等,单机部署的优点是成本低、易于管理,但缺点是性能和可用性有限。
主从复制部署:主从复制是一种常见的高可用性和数据备份方案,在主从复制中,一个MySQL实例作为主服务器(Master),另一个或多个实例作为从服务器(Slave),主服务器处理写操作,并将数据变更复制到从服务器,从服务器可以处理读操作,从而提高系统的读写分离能力,主从复制还可以用于数据备份和灾难恢复。

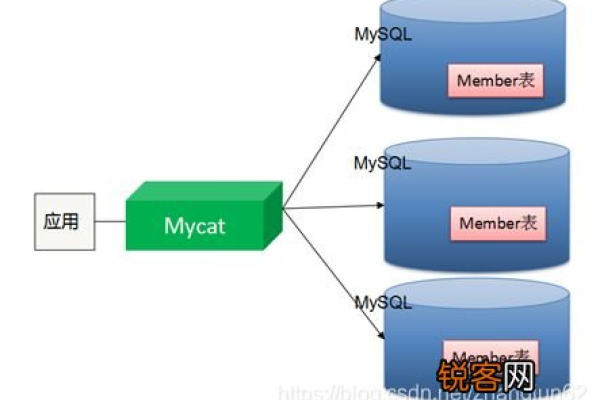
分布式部署:对于大规模应用,可能需要将MySQL部署在多个数据中心或云服务提供商上,分布式部署需要考虑数据一致性、网络延迟、容错机制等问题,常用的分布式数据库解决方案包括MySQL Cluster、Galera Cluster等,这些解决方案提供了自动分片、故障转移等功能,适用于需要高可用性和可扩展性的场景。
MySQL作为一种强大的关系型数据库管理系统,在各行各业中得到了广泛的应用,通过选择合适的书籍进行学习,并结合实际项目的需求进行合理的部署,可以充分发挥MySQL的优势,为业务提供稳定可靠的数据支持。






热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01