迈达斯CDN操作指南,如何操作CDN服务?

迈达斯CDN操作全解析
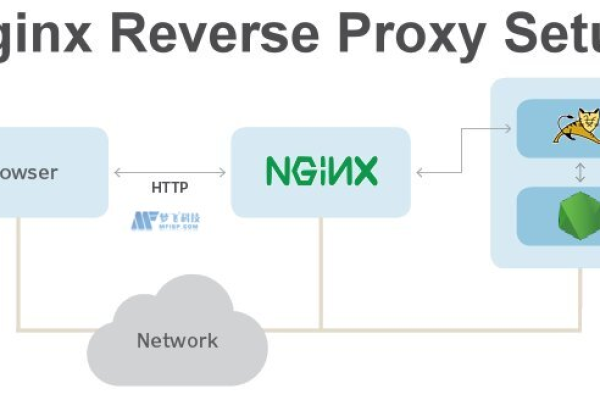
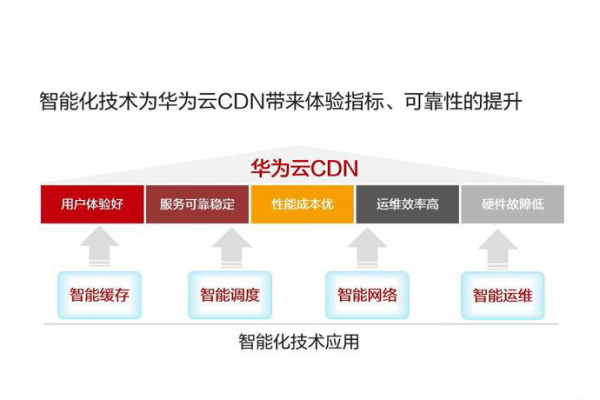
1、CDN节点分布:CDN通过在全球部署多个节点,将网站静态资源缓存到这些节点上,用户访问时,CDN会自动选择最近的节点提供服务,减少数据传输时间。
2、静态资源缓存:静态资源(如图像、CSS文件、JavaScript文件等)不经常更改,适合缓存,CDN将这些资源缓存到各节点上,当用户请求这些资源时,CDN会从最近的节点返回缓存的内容,而不是从原始服务器获取,从而加快访问速度。
二、提高网站可用性
1、负载均衡:CDN通过将流量分散到多个节点上,有效分担了原始服务器的负载,避免了单点故障的发生,当某个节点出现问题时,CDN会自动切换到其他节点,确保用户能够正常访问网站。
2、防止DDoS攻击:CDN还具有防止DDoS(分布式拒绝服务)攻击的功能,通过将流量分散到多个节点,CDN可以有效吸收和缓解DDoS攻击带来的冲击,保证网站的正常运行。
三、增强安全性
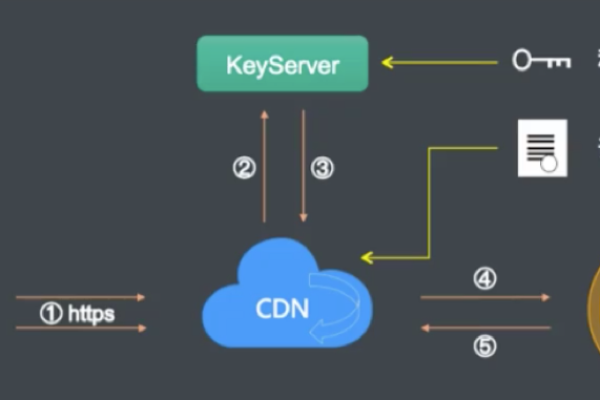
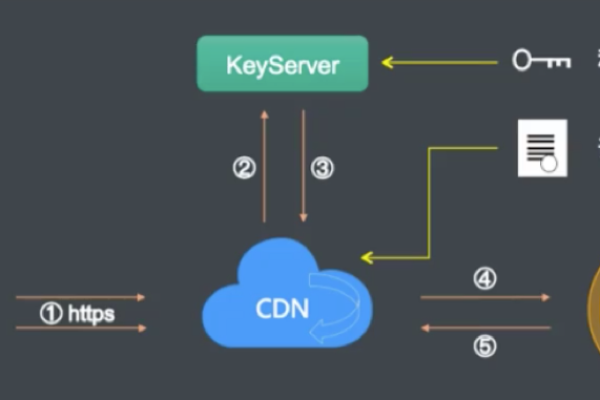
1、HTTPS加密:CDN通常支持HTTPS加密,确保数据在传输过程中不会被窃取或改动,通过启用HTTPS,网站可以提供更安全的浏览环境,提高用户的信任度。
2、防火墙和威胁防护:许多CDN提供商还提供防火墙和威胁防护功能,可以实时监控和过滤反面流量,防止破解攻击和反面软件的载入,这些安全措施可以有效保护网站的安全,减少安全破绽和数据泄露的风险。
四、实际应用步骤
1、选择合适的CDN服务提供商:市场上有许多CDN服务提供商,如Cloudflare、Akamai、Amazon CloudFront等,选择合适的CDN服务提供商需要考虑以下因素:节点分布、服务质量、价格、安全性等。
2、配置CDN服务:选择好CDN服务提供商后,需要进行相应的配置,具体步骤如下:
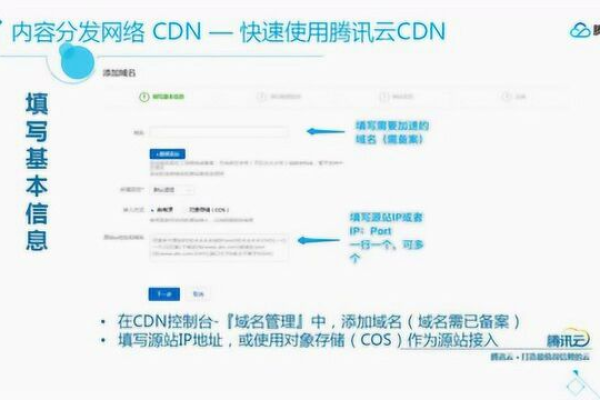
创建账号和域名配置:在CDN服务提供商的网站上创建账号,并将迈达斯网站的域名添加到CDN服务中。

DNS解析配置:将网站域名的DNS解析指向CDN提供的CNAME记录,这样,用户访问网站时,DNS服务器会将请求转发到CDN节点。
缓存策略配置:根据网站的需求,配置CDN的缓存策略,可以设置哪些资源需要缓存,缓存的时间长度等。
HTTPS配置:启用HTTPS,确保数据传输的安全性,可以通过CDN提供商生成和管理SSL证书。
3、监控和优化:配置完成后,需要对CDN的效果进行监控和优化,可以使用CDN服务提供商提供的监控工具,查看网站的访问速度、流量分布、缓存命中率等指标,根据监控结果,进行相应的优化调整。
五、常见问题及解决方案
1、缓存未更新:有时,网站内容更新后,CDN缓存的内容未及时更新,可以通过以下方法解决:
手动刷新缓存:登录CDN服务提供商的管理后台,手动刷新缓存。
设置缓存过期时间:调整缓存策略,设置较短的缓存过期时间,确保内容及时更新。

2、访问速度未显著提升:如果配置了CDN后,访问速度未显著提升,可以考虑以下因素:
节点选择:确保CDN节点分布合理,用户能够从最近的节点获取资源。
缓存策略:检查缓存策略是否合理,确保静态资源被有效缓存。
网络问题:排查用户所在地区的网络问题,确保网络连接畅通。
3、安全问题:使用CDN后,仍需关注网站的安全问题,可以通过以下措施提高安全性:
启用HTTPS:确保数据传输的安全性。
防火墙和威胁防护:配置防火墙和威胁防护,防止反面流量和攻击。

定期更新:定期更新网站和CDN服务,修复安全破绽。
六、相关问题与解答
1、什么是迈达斯CDN?
答:迈达斯CDN是一款功能强大的桥梁设计和分析软件,用于进行复杂的桥梁结构设计和分析,它提供了多种功能模块和工具,帮助工程师实现复杂的计算需求。
2、如何配置迈达斯CDN?
答:配置迈达斯CDN需要先选择合适的CDN服务提供商,然后在该提供商的控制台中进行相应的配置,具体步骤包括创建账号和域名配置、DNS解析配置、缓存策略配置以及HTTPS配置等。

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22